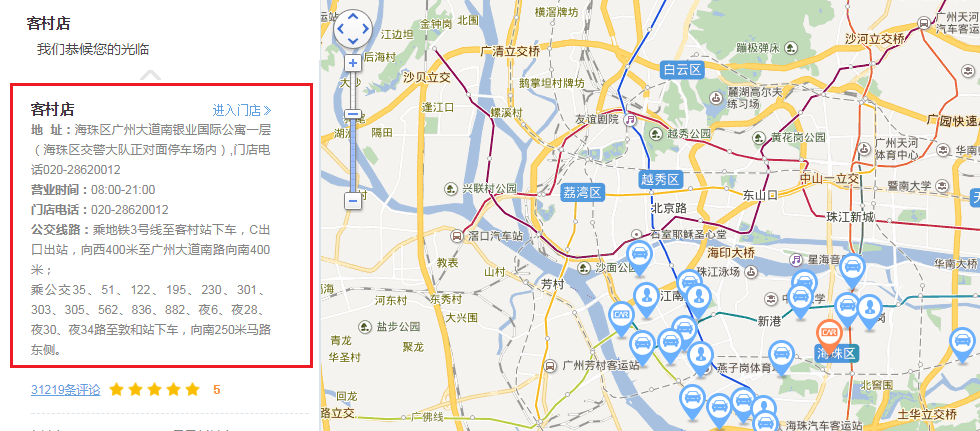
打开神州租车的官网 https://service.zuche.com/ ,在地图上选择广东,然后点击广州,可以看到广州市所有门店的服务点,点击客村店。如图:可以看到客村店的门店地址、联系电话等。
关于爬虫的步骤可以参考: https://qinglianghe.github.io/2017/09/03/python_crawler/
url 请求的过程
请求首页
当发送 https://service.zuche.com/ 请求后,界面上会显示一张地图,如图所示:
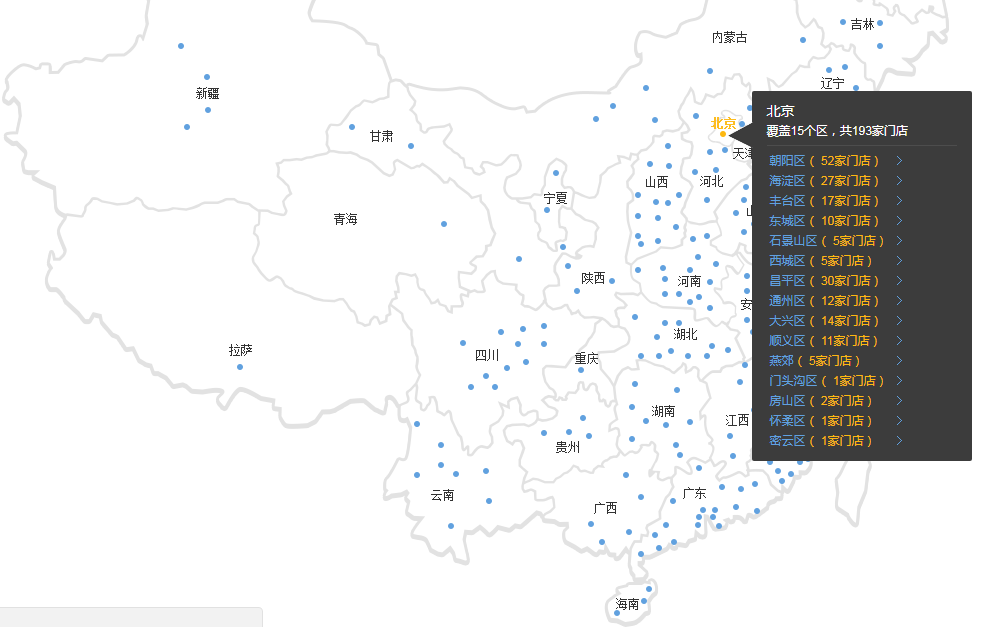
查看对应的html文档,可以看到包含有每个城市的链接地址。如图:

所以可以把上面的html文档中的每个城市的链接提取出来,然后对每个提取的链接分别发起http请求,即可得到对应城市的信息。下面的代码用于提取每个城市的链接:
1 | def get_city_list(data): |
使用BeautifulSoup提取<div class="mapcitylist">后面的所有a标签的内容,tag.string为城市的名称,tag['href']为城市的链接。返回的是一个生成器。
请求城市链接
使用上面提取的城市链接,再次发起http请求。如:上面提取的广州市的链接为:https://guangzhou.zuche.com。返回的页面如图,可以看到广州市所有门店:
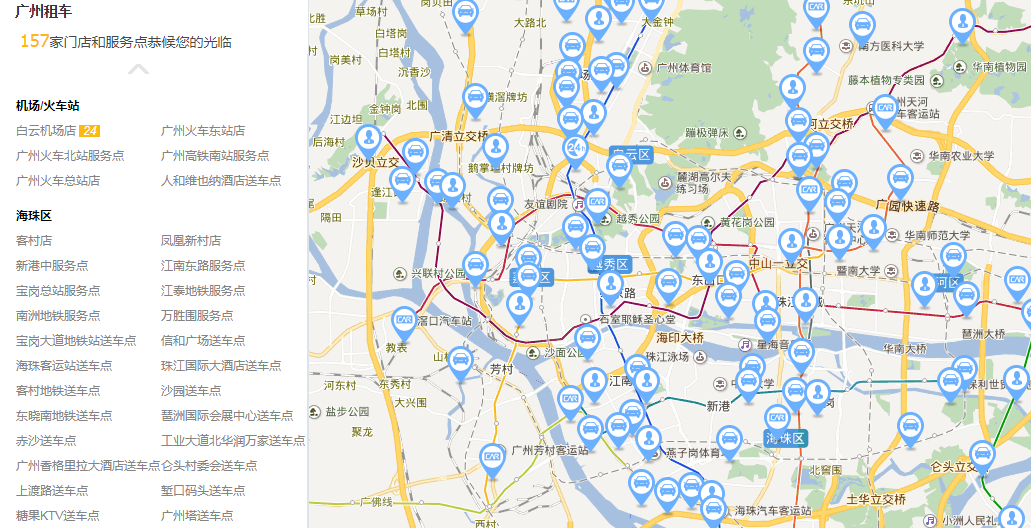
查看对应的html文档,可以看到包含有广州市所有门店的链接地址。如图:

所以可以把上面的html文档中的所有门店的链接提取出来,然后对每个提取的链接分别发起http请求,即可得到对应门店的链接。下面的代码用于提取每个门店的链接:
1 | def get_city_store(data): |
使用BeautifulSoup找出所有id属性符合depLi.*的正则表达式的li标签。对每个li标签提取dd标签的内容,tag.a.string为门店的名称,tag.a['href']为门店的链接。返回的是一个生成器。
请求门店的信息
使用上面提取的门店链接,再次发起http请求。如:上面提取的客村店的链接为:
https://guangzhou.zuche.com/452 返回的页面即是最上面的对应的那张图。查看对应的html文档,可以看到客村店的对应的租车信息:

下面的代码用于门店的信息:
1 | def get_store_details(data): |
使用BeautifulSoup提取<div class="addressInfo">后面的所有span标签的后面的内容。
结果如下
经过上面的爬取,最后可以爬取到神州租车所有的门店信息,如图:

代码如下:
1 | #!/usr/bin/env python3 |
在main函数中首先请求神州租车的首页,然后获得每个城市的链接,再对每个城市的链接,发起http请求,得到每个城市的门店链接,对每个门店的链接再次发次http请求,最后得到门店的信息,并保存结果。
request_url函数用于请求对应的url,它有一个url_decorate装饰器用于打印每次请求的url。在发送请求的时,需要在头部中添加User-Agent,不然服务器会拒绝请求。如果一个url请求超过3次失败,则丢弃这次请求。
save_info函数用于保存结果,每次保存了结果后,都会关闭文件,这会影响效率,实际使用时,可以在所有结果爬取完后再关闭文件。