在Redis的主从复制模式下,当主节点出现故障时,Redis Sentinel能自动完成故障发现和故障转移,并通知应用方,从而实现真正的高可用。
Redis Sentinel
Sentinel节点集合会定期对所有节点进行监控,特别是对主节点的故障实现自动转移。
故障转移的过程
下面以1个主节点、2个从节点、3个Sentinel节点组成的Redis Sentinel为例子进行说明,拓扑结构如图:
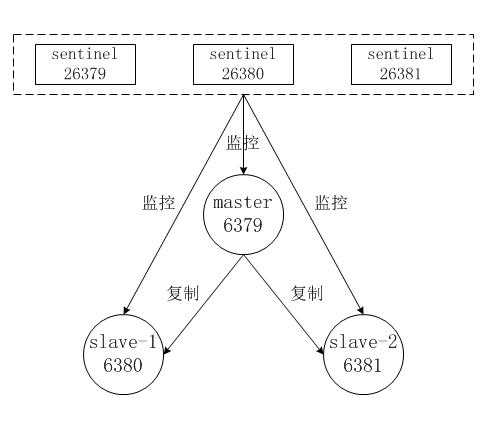
整个故障转移的处理逻辑有下面4个步骤:
主节点出现故障,此时两个从节点与主节点失去连接,主从复制失败。
每个Sentinel节点通过定期监控发现主节点出现了故障。
多个Sentinel节点对主节点的故障达成一致,选举出一个sentinel节点作为领导者负责故障转移。
Sentinel领导者节点执行了主从模式的故障转移。
主从模式的故障转移过程:
主节点发生故障后,客户端连接主节点失败,两个从节点与主节点连接失败造成复制中断。
选出一个从节点,对其执行
slaveof no one命令使其成为新的主节点。原来的从节点成为新的主节点后,更新应用方的主节点信息,重新启动应用方。
命令另一个从节点去复制新的主节点。
待原来的主节点恢复后,让它去复制新的主节点。
Redis Sentinel包含了若个Sentinel节点,这样做也带来了两个好处:
- 对于节点的故障判断是由多个Sentinel节点共同完成,这样可以有效地防止误判。
- Sentinel节点集合是由若干个Sentinel节点组成的,这样即使个别Sentinel节点不可用,整个Sentinel节点集合依然是健壮的。
安装和部署
按上图中的拓扑结构,进行部署。
启动主节点
redis-server /opt/redis/redis_6379.conf
启动两个从节点
在从节点中添加了slaveof配置:
slaveof 127.0.0.1 6379
启动两个从节点:
redis-server /opt/redis/redis_6380.conf
redis-server /opt/redis/redis_6381.conf
确认主从关系
主节点的视角,它有两个从节点,分别是127.0.0.1:6380和127.0.0.1:6381:
redis-cli -h 127.0.0.1 -p 6379 info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=57,lag=0
slave1:ip=127.0.0.1,port=6381,state=online,offset=57,lag=1
master_repl_offset:57
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:56
从节点的视角,它的主节点是127.0.0.1:6379:
redis-cli -h 127.0.0.1 -p 6380 info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:5
master_sync_in_progress:0
slave_repl_offset:407
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
部署Sentinel节点
3个Sentinel节点的部署方法是完全一致的,只是端口不同,下面是redis-sentinel-26379.conf的配置文件:
port 26379
daemonize yes
logfile "26379.log"
dir "./"
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
启动Sentinel节点:
使用redis-sentinel命令:
redis-sentinel redis-sentinel-26379.conf
使用redis-server命令加--sentinel参数:
redis-server redis-sentinel-26379.conf --sentinel
确认
redis-cli -h 127.0.0.1 -p 26379 info Sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
master0:name=mymaster,status=ok,address=127.0.0.1:6379,slaves=2,sentinels=3
从上面info的Sentinel片段来看,Sentinel节点找到了主节点127.0.0.1:6379,发现了它的两个从节点,同时发现Redis Sentinel一共有3个Sentinel节点。
测试故障转移
模拟故障的方法有很多,比较典型的方法有以下几种:
强制杀掉对应节点的进程号,这样可以模拟出宕机的效果。
使用Redis的
debug sleep命令,让节点进入睡眠状态,这样可以模拟阻塞的效果。使用Redis的
shutdown命令,模拟正常的停掉Redis。
使用kill使主节点的进程宕机:
kill 3330
可以看到6380节点晋升为主节点,6381节点成为6380节点的从节点:
查看Sentinel节点:
redis-cli -h 127.0.0.1 -p 26379 info Sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
master0:name=mymaster,status=ok,address=127.0.0.1:6380,slaves=2,sentinels=3
查看6380节点:
redis-cli -h 127.0.0.1 -p 6380 info replication
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6381,state=online,offset=16509,lag=0
master_repl_offset:16642
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:16641
重启6379节点:
redis-server /opt/redis/redis_6379.conf
可以看到6379节点变成了6380的从节点:
redis-cli -h 127.0.0.1 -p 6379 info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6380
master_link_status:up
master_last_io_seconds_ago:0
master_sync_in_progress:0
slave_repl_offset:85237
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
Sentinel节点重新监控6379节点:
redis-cli -h 127.0.0.1 -p 26379 info Sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
master0:name=mymaster,status=ok,address=127.0.0.1:6380,slaves=2,sentinels=3
Sentinel配置
sentinel monitor
sentinel monitor <master-name> <ip> <port> <quorum>
Sentinel节点要监控的是一个名字叫做<master-name>,ip地址和端口为<ip><port>的主节点。
<quorum>代表要判定主节点最终不可达所需要的票数。一般建议将其设置为Sentinel节点的一半加1。同时<quorum>还与Sentinel节点的领导者选举有关,至少要有max(quorum,num(sentinels)/2+1)个Sentinel节点参与选举,才能选出领导者Sentinel。
虽然Sentinel节点的配置中没有看到有关从节点和其余Sentinel节点的配置,但是Sentinel节点会从主节点中获取有关从节点以及其余Sentinel节点的相关信息。
当所有节点启动后,配置文件中的内容将会被重写,体现在三个方面:
- Sentinel节点自动发现了从节点、其余Sentinel节点。
- 去掉了默认配置,例如
parallel-syncs、failover-timeout参数。 - 添加了配置纪元相关参数。
启动后变化为:
port 26379
daemonize yes
logfile "26379.log"
dir "./"
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel config-epoch mymaster 0
sentinel leader-epoch mymaster 0
#发现两个slave节点
sentinel known-slave mymaster 127.0.0.1 6380
sentinel known-slave mymaster 127.0.0.1 6381
#发现两个sentinel节点
sentinel known-sentinel mymaster 127.0.0.1 26380 282a70ff56c36ed56e8f7ee6ada74124140d6f53
sentinel known-sentinel mymaster 127.0.0.1 26381 f714470d30a61a8e39ae031192f1feae7eb5b2be
sentinel current-epoch 0
sentinel down-after-milliseconds
sentinel down-after-milliseconds <master-name> <times>
每个Sentinel节点都要通过定期发送ping命令来判断Redis数据节点和其余Sentinel节点是否可达,如果超过了down-after-milliseconds配置的时间且没有回复,则判定节点不可达,<times>(单位为毫秒)就是超时时间。这个配置是对节点失败判定的重要依据。
down-after-milliseconds虽然以<master-name>为参数,但实际上对Sentinel节点、主节点、从节点的失败判定同时有效。
sentinel parallel-syncs
配置如下:
sentinel parallel-syncs <master-name> <nums>
parallel-syncs用来限制在一次故障转移之后,每次向新的主节点发起复制操作的从节点个数。如果这个参数配置的比较大,那么多个从节点会向新的主节点同时发起复制操作,尽管复制操作通常不会阻塞主节点,但是同时向主节点发起复制,必然会对主节点所在的机器造成一定的网络和磁盘IO开销。
sentinel failover-timeout
sentinel failover-timeout <master-name> <times>
failover-timeout通常被解释成故障转移超时时间,但实际上它作用于故障转移的各个阶段:
如果Redis Sentinel对一个主节点故障转移失败,那么下次再对该主节点做故障转移的起始时间是
failover-timeout的2倍。如果Sentinel节点向选出来的从节点执行
slaveof no one一直失败(例如该从节点此时出现故障),当此过程超过failover-timeout时,则故障转移失败。Sentinel节点还会执行
info命令来确认选出来的节点确实晋升为主节点,如果此过程执行时间超过failovertimeout时,则故障转移失败。命令其余从节点复制新的主节点,执行时间超过了
failover-timeout(不包含复制时间),则故障转移失败。注意即使超过了这个时间,Sentinel节点也会最终配置从节点去同步最新的主节点。
sentinel auth-pass
sentinel auth-pass <master-name> <password>
如果Sentinel监控的主节点配置了密码,sentinel auth-pass配置通过添加主节点的密码,防止Sentinel节点对主节点无法监控。
sentinel notification-script
sentinel notification-script <master-name> <script-path>
在故障转移期间,当一些警告级别的Sentinel事件发生(指重要事件,例如-sdown:客观下线、-odown:主观下线)时,会触发对应路径的脚本,并向脚本发送相应的事件参数。
sentinel client-reconfig-script
sentinel client-reconfig-script的作用是在故障转移结束后,会触发对应路径的脚本,并向脚本发送故障转移结果的相关参数。和notification-script类似。
当故障转移结束,每个Sentinel节点会将故障转移的结果发送给对应的脚本,具体参数如下:
<master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port>
<master-name>:主节点名<role>:Sentinel节点的角色,分别是leader和observer,leader代表当前Sentinel节点是领导者,是它进行的故障转移;observer是其余Sentinel节点。<from-ip>:原主节点的ip地址。<from-port>:原主节点的端口。<to-ip>:新主节点的ip地址。<to-port>:新主节点的端口。
部署技巧
Sentinel节点不应该部署在一台物理“机器”上。
部署至少三个且奇数个的Sentinel节点。
如果Sentinel节点集合监控的是同一个业务的多个主节点集合,那么使用一套Sentinel,否则一般建议采用每个主节点配置一套Sentinel。
API
Sentinel节点是一个特殊的Redis节点,它有自己专属的API。
sentinel masters
展示所有被监控的主节点状态以及相关的统计信息:
127.0.0.1:26379> sentinel masters
sentinel master (master name)
展示指定<master name>的主节点状态以及相关的统计信息:
127.0.0.1:26379> sentinel master mymaster
sentinel slaves (master name)
展示指定<master name>的从节点状态以及相关的统计信息:
127.0.0.1:26379> sentinel slaves mymaster
sentinel sentinels (master name)
展示指定<master name>的Sentinel节点集合(不包含当前Sentinel节点):
127.0.0.1:26379> sentinel sentinels mymaster
sentinel get-master-addr-by-name (master name)
返回指定<master name>主节点的IP地址和端口:
127.0.0.1:26379> sentinel get-master-addr-by-name mymaster
sentinel reset (pattern)
当前Sentinel节点对符合<pattern>(通配符风格)主节点的配置进行重置,包含清除主节点的相关状态(例如故障转移),重新发现从节点和Sentinel节点。
127.0.0.1:26379> sentinel reset mymaster-
sentinel failover (master name)
对指定<master name>主节点进行强制故障转移(没有和其他Sentinel节点“协商”),当故障转移完成后,其他Sentinel节点按照故障转移的结果更新自身配置。
127.0.0.1:26379> sentinel failover mymaster
sentinel ckquorum (master name)
检测当前可达的Sentinel节点总数是否达到<quorum>的个数。
127.0.0.1:26379> sentinel ckquorum mymaster-
sentinel flushconfig
将Sentinel节点的配置强制刷到磁盘上
sentinel remove (master name)
取消当前Sentinel节点对于指定<master name>主节点的监控。
sentinel is-master-down-by-addr
Sentinel节点之间用来交换对主节点是否下线的判断,根据参数的不同,还可以作为Sentinel领导者选举的通信方式。
实现原理
三个定时监控任务
Redis Sentinel通过三个定时监控任务完成对各个节点发现和监控:
每隔10秒,每个Sentinel节点会向主节点和从节点发送info命令获取最新的拓扑结构。
这个定时任务的作用具体可以表现在三个方面:
- 通过向主节点执行info命令,获取从节点的信息,这也是为什么Sentinel节点不需要显式配置监控从节点。
- 当有新的从节点加入时都可以立刻感知出来。
- 节点不可达或者故障转移后,可以通过info命令实时更新节点拓扑信息。
每隔2秒,每个Sentinel节点会向Redis数据节点的__sentinel__:hello频道上发送该Sentinel节点对于主节点的判断以及当前Sentinel节点的信息,同时每个Sentinel节点也会订阅该频道,来了解其他Sentinel节点以及它们对主节点的判断。
这个定时任务可以完成以下两个工作:
- 发现新的Sentinel节点:通过订阅主节点的
__sentinel__:hello了解其他的Sentinel节点信息,如果是新加入的Sentinel节点,将该Sentinel节点信息保存起来,并与该Sentinel节点创建连接。 - Sentinel节点之间交换主节点的状态,作为后面客观下线以及领导者选举的依据。
每隔1秒,每个Sentinel节点会向主节点、从节点、其余Sentinel节点发送一条ping命令做一次心跳检测,来确认这些节点当前是否可达。
通过上面的定时任务,Sentinel节点对主节点、从节点、其余Sentinel节点都建立起连接,实现了对每个节点的监控,这个定时任务是节点失败判定的重要依据。
主观下线
每个Sentinel节点会每隔1秒对主节点、从节点、其他Sentinel节点发送ping命令做心跳检测,当这些节点超过down-after-milliseconds没有进行有效回复,Sentinel节点就会对该节点做失败判定,这个行为叫做主观下线。
客观下线
当Sentinel主观下线的节点是主节点时,该Sentinel节点会通过sentinel ismaster-down-by-addr命令向其他Sentinel节点询问对主节点的判断,当超过<quorum>个数,Sentinel节点认为主节点确实有问题,这时该Sentinel节点会做出客观下线的决定。
领导者Sentinel节点选举
Sentinel节点之间会做一个领导者选举的工作,选出一个Sentinel节点作为领导者进行故障转移的工作。Redis使用了Raft算法实现领导者选举。
一个Redis Sentinel进行领导者选举的大致思路:
- 每个在线的Sentinel节点都有资格成为领导者,当它确认主节点主观下线时候,会向其他Sentinel节点发送
sentinel is-master-down-by-addr命令,要求将自己设置为领导者。 - 收到命令的Sentinel节点,如果没有同意过其他Sentinel节点的
sentinel is-master-down-by-addr命令,将同意该请求,否则拒绝。 - 如果该Sentinel节点发现自己的票数已经大于等于
max(quorum,num(sentinels)/2+1),那么它将成为领导者。 - 如果此过程没有选举出领导者,将进入下一次选举。
故障转移
领导者选举出的Sentinel节点负责故障转移,具体步骤如下:
- 在从节点列表中选出一个节点作为新的主节点,选择方法如下:
- 过滤:“不健康”(主观下线、断线)、5秒内没有回复过Sentinel节点ping响应、与主节点失联超过
down-after-milliseconds*10秒。 - 选择slave-priority(从节点优先级)最高的从节点列表,如果存在则返回,不存在则继续。
- 选择复制偏移量最大的从节点(复制的最完整),如果存在则返回,不存在则继续。
- 选择runid最小的从节点。
Sentinel领导者节点会对第一步选出来的从节点执行
slaveof no one命令让其成为主节点。Sentinel领导者节点会向剩余的从节点发送命令,让它们成为新主节点的从节点,复制规则和
parallel-syncs参数有关。Sentinel节点集合会将原来的主节点更新为从节点,并保持着对其关注,当其恢复后命令它去复制新的主节点。