Kafka是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式消息系统。
Kafka
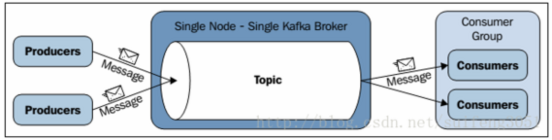
Kafka对消息保存是根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,多个Kafka节点可以组成集群,每个节点称为Broker。
Broker
一个Kafka节点就是一个Broker,多个Broker可以组成一个Kafka集群。Broker的主要工作就是接收生产者发送来的消息,分配offset,然后将数据保存到磁盘上,消费者会并从Broker拉数据。
每个Kafka集群会选出一个Broker来担任Controller,Controller是Kafka集群的指挥中心,其他的Broker则听从Controller指挥实现相应的功能。Controller负责管理分区的状态、管理每个分区的副本状态、监听zookeeper中数据的变化等。当Controller出现了故障的时候就重新选举新的Controller。
Topic
Topic是用于存储消息的逻辑概念,Topic可以看做是一个消息的集合。每个Topic可以有多个生产者向其中push消息,也可以有多个消费者向其中pull消息。
Partition
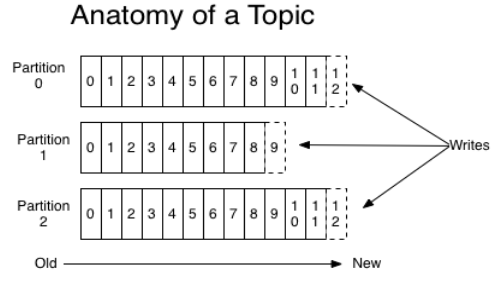
每一个Topic都可以划分成多个分区(每一个Topic都至少有一个分区),kafka将尽量把不同的分区会分配在不同的Broker上,以对Kafka进行水平扩展从而增加Kafka的并行处理能力。
Kafka会根据分区规则选择把消息存储到哪个分区中,如果分区规则设置的合理,那么所有的消息将会被均匀的分布到不同的分区中,这样就实现了负载均衡和水平扩展。
每个Partition为一个目录,Partition命名的规则为topic名称+有序序号,序号从0开始,序号最大值为Partition数量减1。
每一个分区都是一个顺序的、不可变的消息队列, 并且可以持续的添加。分区中的消息都被分了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的。
Producer
生产者主要是生产消息,并将消息按照一定的规则推送到Topic的分区中。
Consumer
消费者主要是从Topic中拉取消息,并对消息进行消费。Consumer维护着上一次读到哪里的offset信息。
Consumer Group
在Kafka中,多个Consumer可以组成一个Consumer Group。
- Partition中的每个消息只能被
Consumer group中的一个consumer消费。 - 如果一个消息可以被多个consumer消费的话,那么这些consumer必须在不同的
Consumer group,相当于发布-订阅式模式。 - 如果一个消费者故障。分配给它的分区将重新分配给同一个分组中其他的消费者。
Consumer和Partition的关系
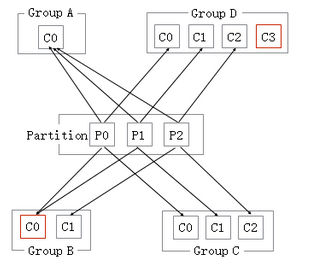
在一个Consumer group下,无论有多少个consumer,这个Consumer group一定会把这个topic下所有的Partition都消费。
一个conusmer消费多个Partition:如下图Group A、Group B, 当
Consumer group里面的consumer数量小于这个Topic下的Partition数量。conusmer消费等于Partition的个数:如下图Group C,此时效率是最高的,每个Partition都有一个consumer。
consumer数量大于Partition的个数:如下图Group D,会出现有一个consumer空闲。
Log
分区在逻辑上对应着一个Log,当生产者将消息写入分区的时候,实际上就是写入到了一个Log中。Log是一个逻辑概念,对应的是一个磁盘上的文件夹。Log由多个Segment组成,每一个Segment又对应着一个log为后缀的数据文件和一个index为后缀的索引文件。
Segment file
每一个log文件和一个index文件相对应,这一对文件就是一个segment file。
Segment文件命名的规则:第一个segment从0(20个0)开始,后续的每一个segment文件名是上一个segment文件中最后一条消息的offset值。

index文件是对log文件的索引,里面存储了对应log文件里的数据条数和其对应的文件偏移量的映射关系。
index并不是对每一个数据都记录的文件偏移,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。

如上图左半部分是index索引文件,里面存储的是一对一对的key-value,4Bytes的offset相对偏移(key),4Bytes的物理文件偏移(value)。
以索引文件6,1407为例,6代表该文件的第6条数据,就是该Partition内offset为(368769+6)的这条数据,可以从该log文件的1407位置开始读。
Log保存的时机和删除策略
日志会串行的追加消息到最后的一个文件。当它达到配置文件中设置的大小(默认为1GB),就会生成新的文件。
Kafka会将数据写入文件系统的PageCache(页缓存),并支持将数据从操作系统缓存刷新到磁盘上。日志的刷新策略可以采用2个配置参数:M,它定义了强制OS刷新文件到磁盘之前主动写入的消息数量。S,它定义了几秒后强制刷新。这样提供了耐久性的保障。当系统崩溃时候,丢失最多M消息,或S秒的数据。
使用应用程序级别刷新设置的缺点是它的磁盘使用模式效率较低(它给操作系统减少了重新排序写操作的余地),并且可能引入延迟,因为fsync在大多数Linux文件系统中阻塞写入文件。Kafka默认的配置,完全禁用fsync应用。这意味着依赖操作系统和Kafka自己的后台刷新,数据的保障可以通过副本来保证。
Kafka会启动一个后台线程定期扫描日志列表,把过期的日志删除。删除策略是删除修改时间在N天之前的日志(按时间删除),也可以使用另外一个策略:保留最后的N GB数据的策略(按大小删除)。
replication
Kafka可以为每个Topic分区设置副本的个数,从而可以备份消息。Kafka的副本具有一定的同步机制,在每个副本集合中,都会选举出一个副本作为Leader副本。
Kafka中所有的读写请求都由选举出的Leader副本处理,其他的都作为Follower副本,Follower副本仅仅是从Leader副本中把数据拉取到本地之后,同步更新到自己的Log中。
当Leader发生故障时,会在这些Follower中选取出新的Leader,在任何时候,只要至少有一个同步Follower副本活着,就能保障在故障时消息仍然可用。
Kafka的节点活着的判定:
一个节点必须能维持与zookeeper的会话(通过zookeeper的心跳机制)
如果它是一个Follower,它必须复制Leader并且不能落后”太多”。
消息传递保障
Producer发送消息时,会发送到生产者的缓存中,缓存的大小是可以通过配置设定。默认缓存是立即发送的,即使缓存空间还没有满。如果想减少请求的数量,可以配置生产者在发送消息且缓冲区还没有满时,等待一段时间再发送,这样可以一次传输多条消息,从而可以提高消息的传输效率,这相当于TCP的Nagle算法。如果这期间,Producer发生异常,缓存的消息将会丢失。
当Producer发送消息到Leader后,可以通过配置request.required.acks来设置消息的应答机制:
acks=0,那么生产者将不等待任何消息确认。在这种情况下不能保障消息被服务器接收到。并且重试机制不会生效(因为客户端不知道故障了没有)。每个消息返回的offset始终设置为-1。
acks=1,这意味着Leader写入消息到本地日志就立即响应,而不等待所有Follower应答。在这种情况下,如果响应消息之后但Follower还未复制之前Leader立即故障,那么消息将会丢失。
acks=all,这意味着Leader将等待所有副本同步后应答消息。此配置保障消息不会丢失(只要至少有一个同步的副本)。这是最强壮的可用性保障。等价于acks=-1。
Consumer从分区中消费消息时,会维护着上一次消费到哪里的offset信息。offset的提交可以自动或手动提交:
自动提交offset的频率可以由Consumer设置,例如设置每100ms提交一次,但是如果在这100ms中消息未被处理完成,Consumer发生异常,offset已经提交了,则消息会发生丢失。
手动提交offset有可能会出现消息重复,例如:当Consumer获得消息,将消息写进数据库之后,但还未提交offset,这时出现Consumer出现故障,则会出现最后一批数据重复,这种方式就是所谓的“至少一次”保证,在故障情况下,可以重复。