protobuf是由Google开源的一种轻便高效的结构化数据存储格式,与平台无关、语言无关、可扩展、可用于通讯协议和数据存储等领域。与xml和json相比,它序列化后的数据的大小更小、编解码速度更快。
安装
参考:https://github.com/protocolbuffers/protobuf/blob/master/src/README.md
安装完成后,执行如下命令,查看protobuf是否安装成功:
[heql@ubuntu protobuf]$ protoc --version
libprotoc 3.0.0
定义消息类型
当用protobu描述结构化数据时,需要编写.proto文件,一个结构化数据称为message。如下是一个描述Person的message,包含name和age成员:
1 | syntax = "proto3"; |
syntax = "proto3"表示使用proto3语法:如果没有指定这个,编译器会使用proto2。
字段类型
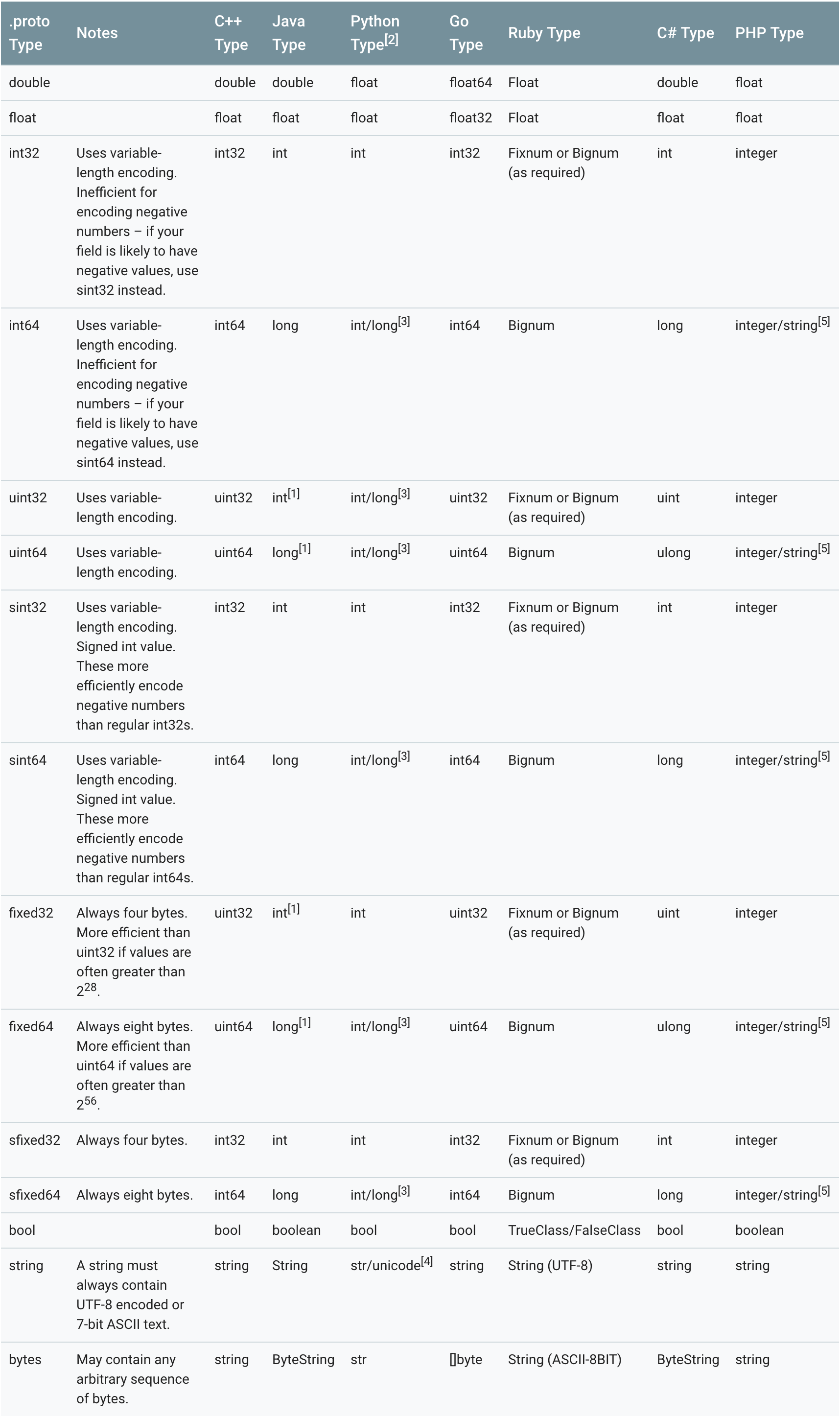
如上面的Person的message,定义了一个string类型的name字段和一个int32类型的age字段。字段可以指定为其他类型,如下表展示了定义于.proto文件中的类型,与之对应的、在自动生成的访问类中定义相应语言的类型。字段的类型也可以为枚举或其他消息类型。
字段的 id
每个字段都有唯一的一个id。这些id是用来在消息的二进制格式中识别各个字段的,一旦开始使用就不能够再改变。注:[1,15]之内的id在编码的时候会占用一个字节。[16,2047]之内的id则占用2个字节。所以应该为那些频繁出现的消息元素保留[1,15]之内的id。切记:要为将来有可能添加的、频繁出现的id预留一些id。
最小的id可以从1开始,最大到2^29 - 1 or 536,870,911。不可以使用其中的[19000-19999] (从FieldDescriptor::kFirstReservedNumber到 FieldDescriptor::kLastReservedNumber) 的id, Protobuf协议实现中对这些进行了预留。如果非要在.proto文件中使用这些预留id,编译时就会报警。同样你也不能使用早期保留的id。
指定字段规则
proto3 所指定的消息字段修饰符必须是如下之一:
- singular:消息格式中该字段可以有0个或1个值(不超过1个)
- repeated: 在一个格式良好的消息中,这种字段可以重复任意多次(包括0次),重复的值的顺序会被保留
如果字段中没有指定修饰符,则默认为singular,如上面的name、age字段。
编译 .proto 文件
写好proto文件之后就可以用 Protobuf 编译器将该文件编译成目标语言了,如下命令:
protoc --cpp_out=. person.proto
--cpp_out=. 表示生成的目标的语言为C++,生成的文件放在当前目录下。其他语言类似,如--python_out,表示生成python代码。
运行上面的命令,则会生成两个文件:
- person.pb.h:定义了 C++ 类的头文件
- person.pb.cc:C++ 类的实现文件
在生成的头文件中,定义了一个C++类Person,这个类提供了对消息进行操作的接口。如下是对生成Person类定义的常用方法的说明性注释:
1 | class Person : public ::google::protobuf::Message { |
使用 protobuf
编译生成了对应的目标代码后,就可以使用相应的接口函数,操作message的字段,如下代码:
1 |
|
上面的代码,在为对象p1的字段设置完值后,把p1序列化到动态内存中,对象p2再从动态内存中反序列化回来。
编译运行程序,输出结果:
[heql@ubuntu protobuf]$ g++ person.cc person.pb.cc -lprotobuf
[heql@ubuntu protobuf]$ ./a.out
name = lisa, age = 18
除了序列化到动态内存中,protobuf还提供其他序列化接口,如:SerializeToString、SerializeToCodedStream序列化到文件等接口。如下代码是把对象p序列化到person.bin文件中:
1 |
|
下面的代码是从person.bin文件,反序列化对象p:
1 |
|
编译运行程序,输出结果:
[heql@ubuntu protobuf]$ g++ writer.cc person.pb.cc -o writer -lprotobuf
[heql@ubuntu protobuf]$ g++ reader.cc person.pb.cc -o reader -lprotobuf
[heql@ubuntu protobuf]$ ./writer
[heql@ubuntu protobuf]$ ./reader
name = lisa, age = 18
repeated 修饰的字段
repeated修饰的字段,表示这个字段可以重复任意多次(包括0次),重复的值的顺序会被保留。如下面的代码为Person添加一个repeated的email字段:
1 | syntax = "proto3"; |
编译proto文件,生成的C++代码如下:
1 | class Person : public ::google::protobuf::Message { |
访问email生成的接口函数,如下代码:
1 |
|
编译运行程序,输出结果:
[heql@ubuntu protobuf]$ g++ person.cc person.pb.cc -lprotobuf
[heql@ubuntu protobuf]$ ./a.out
name = lisa, age = 18
email = test@gmail.com
email = test@qq.com
email = test@163.com
枚举类型
如下面的代码为Person添加一个枚举类型的gender字段:
1 | syntax = "proto3"; |
编译proto文件,生成的枚举类型的gender字段的C++代码如下:
1 | enum Person_Gender { |
访问gender生成的接口函数,如下代码:
1 |
|
编译运行程序,输出结果:
[heql@ubuntu protobuf]$ g++ person.cc person.pb.cc -lprotobuf
[heql@ubuntu protobuf]$ ./a.out
name = lisa, age = 18
email = test@gmail.com
email = test@qq.com
email = test@163.com
male = 1
默认值
在proto3中,如果没有为相应的字段的赋值,则对应的字段使用默认值:
- string,默认是一个空string
- 对于bytes,默认是一个空的bytes
- 对于bool,默认是false
- 对于数值类型,默认是0
- 对于枚举,默认是第一个定义的枚举值,必须为0
- 对于消息类型(message),域没有被设置,确切的消息是根据语言确定的
- repeated的字段默认是null, 空的列表
如下代码,Person使用默认值:
1 |
|
编译运行程序,输出结果:
[heql@ubuntu protobuf]$ g++ person.cc person.pb.cc -lprotobuf
[heql@ubuntu protobuf]$ ./a.out
name = , age = 0
email_size = 0
male = 0
嵌套类型
可以在其他消息类型中定义、使用消息类型,下面的代码,在Peron消息中定义了一个Address消息:
1 | syntax = "proto3"; |
编译proto文件,会生成Person_Address类和Person类,Person_Address类生成字段country和city的访问函数,Person类生成Person_Address类的访问函数:
1 | class Person_Address : public ::google::protobuf::Message { |
访问Address生成的接口函数,如下代码:
1 |
|
编译运行程序,输出结果:
[heql@ubuntu protobuf]$ g++ person.cc person.pb.cc -lprotobuf
[heql@ubuntu protobuf]$ ./a.out
name = lisa, age = 18
email = test@gmail.com
email = test@qq.com
email = test@163.com
male = 1
address:
country = China, city = GuangZhou
repeated 嵌套类型
在Peron消息中定义了一个repeated修饰的PhoneNumber消息:
1 | syntax = "proto3"; |
编译proto文件,会生成Person_PhoneNumber类,Person_PhoneNumber类生成字段number和type的访问函数,Person类生成Person_PhoneNumber类的访问函数:
1 | class Person_PhoneNumber : public ::google::protobuf::Message { |
访问phone_number生成的接口函数,如下代码:
1 |
|
编译运行程序,输出结果:
[heql@ubuntu protobuf]$ g++ person.cc person.pb.cc -lprotobuf
[heql@ubuntu protobuf]$ ./a.out
name = lisa, age = 18
email = test@gmail.com
email = test@qq.com
email = test@163.com
male = 1
address:
country = China, city = GuangZhou
phone:
type = 0, number = 136********
type = 1, number = 020-*******
type = 2, number = 159********
遍历repeated字段时,也可以使用的迭代器进行遍历,如下代码:
1 | printf("phone:\n"); |
导入定义
可以通过导入其他.proto文件中的定义来使用它们。要导入其他.proto文件的定义,需要在你的文件中添加一个导入声明,如下面,是在AddressBook.proto文件中导入Person.proto:
1 | syntax = "proto3"; |
保留标识符(Reserved)
如果你通过删除或者注释所有域,以后的用户在更新这个类型的时候可能重用这些标识号。如果你使用旧版本加载相同的.proto文件会导致严重的问题,包括数据损坏、隐私错误等等。现在有一种确保不会发生这种情况的方法就是为字段tag指定reserved标识符,protocol buffer的编译器会警告未来尝试使用这些域标识符的用户。
1 | message Foo { |
Map 类型
在proto3支持Map类型,其中key_type可以是任意Integer或者string类型(所以,除了floating和bytes的任意标量类型都是可以的)value_type可以是任意类型。
- Map字段不能是repeated
- 序列化后的顺序和map迭代器的顺序是不确定的
- 当为.proto文件产生生成文本格式的时候,map会按照key 的顺序排序,数值化的key会按照数值排序
- 不支持重复的key
如下代码,把上面的PhoneNumber字段改成用Map类型:
1 | syntax = "proto3"; |
编译proto文件,生成Map类型的访问函数:
1 | class Person : public ::google::protobuf::Message { |
访问Map类型生成的接口函数,如下代码:
1 |
|
编译运行程序,输出结果:
[heql@ubuntu protobuf]$ g++ person.cc person.pb.cc -lprotobuf
[heql@ubuntu protobuf]$ ./a.out
name = lisa, age = 18
email = test@gmail.com
email = test@qq.com
email = test@163.com
male = 1
address:
country = China, city = GuangZhou
phone:
type = 0, number = 136********
type = 1, number = 020-*******
type = 2, number = 159********
其他
在proto3中还支持Any类型、Oneof特性等。详情可以参考官方文档。