正排索引
正排索引记录的是文档Id到文档内容、单词的关联关系。也就是说可以通过Id获取到文档的内容。
如下记录着文档ID为1、2分别对应的文档内容:
| 文档 ID | 文档内容 |
|---|---|
| 1 | The quick brown fox jumped over the lazy dog |
| 2 | Quick brown foxes leap over lazy dogs in summer |
倒排索引
倒排索引记录的是单词到文档Id的关联关系。也就是说通过单词搜索到文档Id。
如下是将上面的内容进行分词后,创建的一个倒排索引列表:
| 单词 | 文档ID列表 |
|---|---|
| Quick | 2 |
| The | 1 |
| brown | 1,2 |
| dog | 1 |
| dogs | 2 |
| fox | 1 |
| foxes | 2 |
| in | 2 |
| jumped | 1 |
| lazy | 1,2 |
| leap | 2 |
| over | 1,2 |
| quick | 1 |
| summer | 2 |
| the | 1 |
查询流程
使用倒排索引查询包含brown的文档:
通过倒排索引获得
brown对应的文档ID为1和2通过正排索引查询文档id为1和2对应的文档内容
将查询的最终结果返回给用户
倒排索引组成
倒排索引是搜索引擎的核心,主要包含两部分:
单词词典(Term Dictionary)
倒排列表(Posting List)
单词词典
单词词典(Term Dictionary)是倒排索引的重要组成,
记录所有文档的单词,一般比较大
记录单词到倒排列表的关联信息
单词字典的实现一般是用B+ Tree
倒排列表
倒排列表(Posting List)记录了单词对应的文档集合,由倒排索引项(Posting)组成。
排索引项(Posting)主要包含如下信息:
文档ID, 用于获取原始信息
单词频率(TF,Term Frequency),记录该单词在文档中出现的次数,用于后续的相关性算分
位置(Position),记录单词在文档的分词位置
偏移(Offset),记录单词在文档的开始和结束位置
如brown单词对应的倒排列表如下:
| 文档ID | 单词频率 | 位置 | 偏移 |
|---|---|---|---|
| 1 | 1 | 2 | (10, 14) |
| 2 | 1 | 1 | (6, 10) |
分词
分词是指将文本转换成一系列单词(term or token)的过程,也可以叫做文本分析,在elasticsearch里面称为Analysis。
分词器
分词器是elasticsearch中专门处理分词的组件,英文为Analyzer,它的组成如下:
Character Filters: 针对原始文本进行处理,比如去除html特殊标记符
Tokenizer: 将原始文本按照一定规格切分为单词
Token Filters: 针对tokenizer处理的单词再加工,比如转换成小写、删除或新增等处理
分词器调用的顺序
上面三个分词的组件调用的是有顺序,最先调用的是Character Filters、然后是Tokenizer、最后是Token Filters:
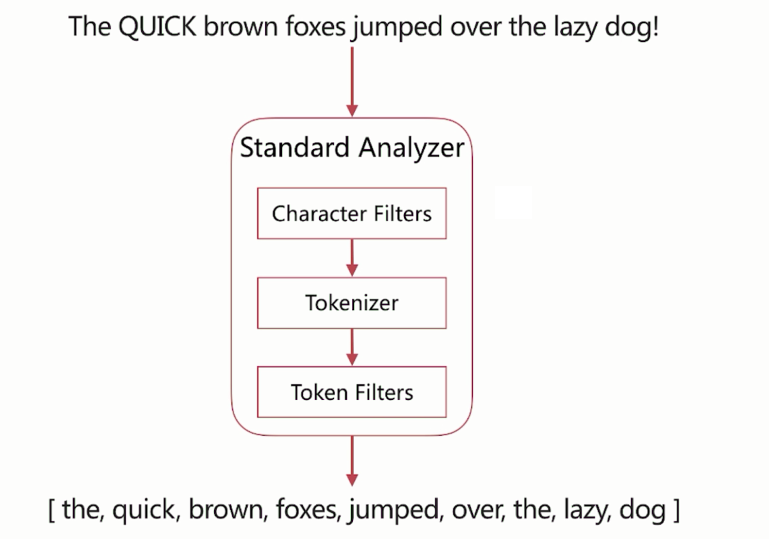
Analyze API
elasticsearch提供了一个测试分词的api接口,方便验证分词效果。
可以直接指定analyzer进行测试
可以直接指定索引中的字段进行测试
可以自定义分词器进行测试
直接指定analyzer进行测试
如下指定analyzer为standard,对文本hello world进行分词:
1 | POST /_analyze |
服务器返回以下结果,token:分词的结果、start_offset:起始偏移、end_offset:结束偏移、position:分词位置。
1 | { |
指定索引中的字段进行测试
当创建好索引后发现某一字段的查询和预期不一样,就可以对这个字段进行分词测试。
如下对test_index的username字段进行测试:
1 | POST /test_index/_analyze |
输出的结果和上面是一样的。
预定义分词器
elasticsearch内置了很多分词器,如:Standard、Simple、Whitespace、Stop、Keyword、Pattern、Language,可以直接使用。
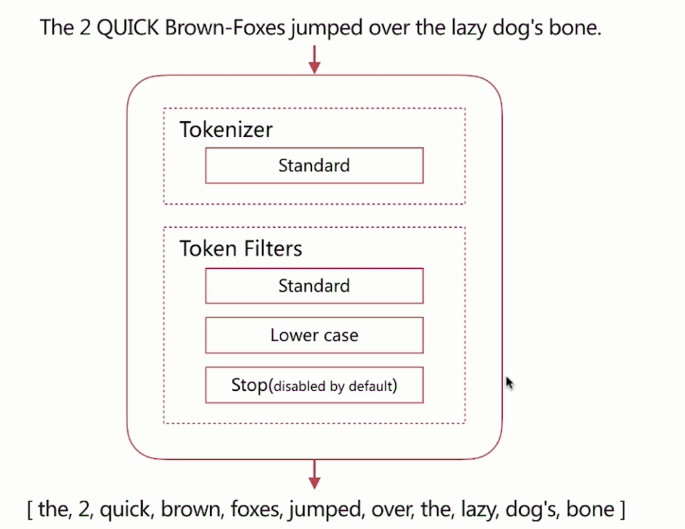
Standard
默认分词器,具有按词切分、支持多语言、转化为小写等特点。
standerd将stop word默认关闭了,stop word就是例如and、the、or这种词,可以通过配置将它打开。这些词还是会在分词后保留。
如下图,输入文本 The 2 Quick Brown-Foxes jumped over the lazy dog's bone.,经过standerd分词器分词后的结果为:[the, 2, quick, brown, foxes, over, the, lazy, dog's, bone]
进行测试时,把analyzer设置为standard即可:
1 | POST /_analyze |
服务器返回的结果为:
1 | { |
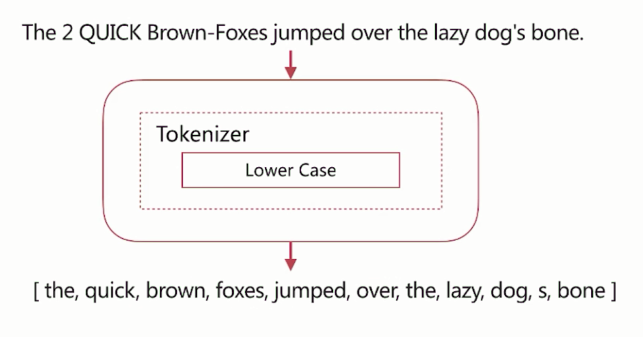
simple
按照非字母切分、小写处理特点。
如下图,上面的文本调用simple分词器,输出的结果:
进行测试时,把analyzer设置为simple即可:
1 | POST /_analyze |
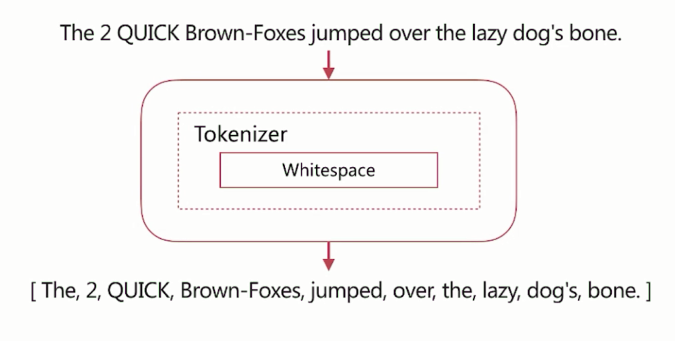
whitespace
按照空格切分。
如下图,上面的文本调用whitespace分词器,输出的结果:
进行测试时,把analyzer设置为whitespace即可:
1 | POST /_analyze |
stop
和simple分词器相比,多了stop word处理,比如英文的:the、an、中文的:的、这等stop word都会被去除。
如下图,上面的文本调用stop分词器,输出的结果:
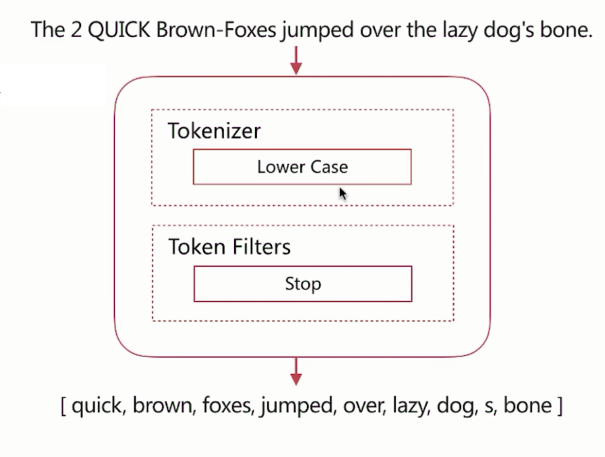
进行测试时,把analyzer设置为stop即可:
1 | POST /_analyze |
keyword
不分词,直接将输入作为一个单词输出。
如下图,上面的文本调用keyword分词器,输出的结果:
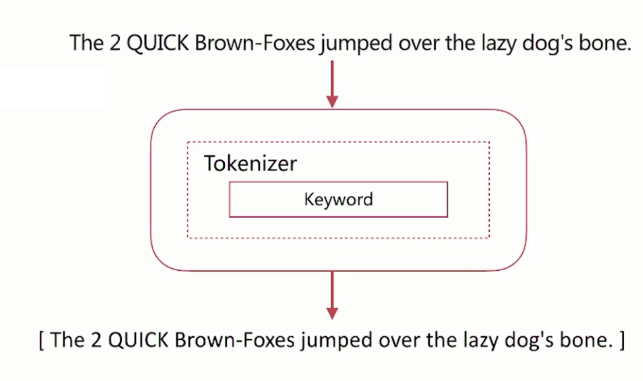
进行测试时,把analyzer设置为keyword即可:
1 | POST /_analyze |
pattern
通过正则表达式自定义分隔符,默认是\W+,即非字词的符号作为分隔符,小写转化 。
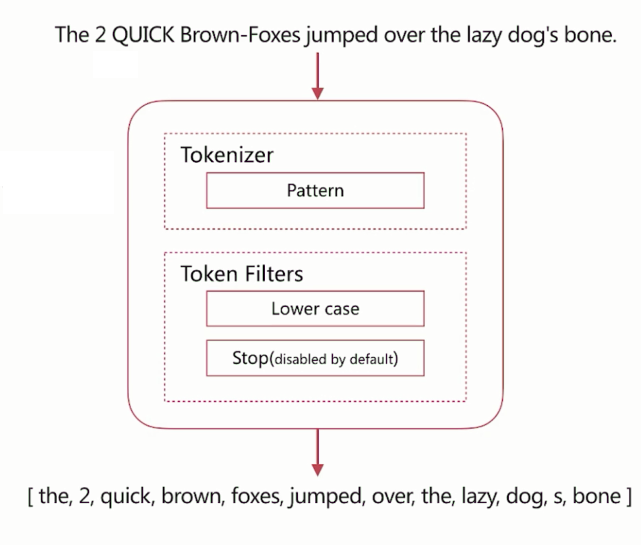
进行测试时,把analyzer设置为pattern即可:
1 | POST /_analyze |
中文分词
在这里以ik为例,首先使用下面的命令,安装ik分词器:
[heql@ubuntu elasticsearch-6.5.0]$ ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.5.0/elasticsearch-analysis-ik-6.5.0.zip
重新启动Elastic,就会自动加载这个新安装的插件。
新建一个Index,指定需要使用ik分词的字段。如下在创建profile Index时,指定user、title、desc字段的analyzer(分词器)、search_analyzer(搜索词的分词器)为ik_max_word分词器:
1 | PUT /profile |
自定义分词
当自带的分词无法满足需求的时候,就需要自定义分词。
自定义分词就是通过自定义Character Filters、Tokenizer和Token Filter实现。
Character Filters
在Tokenizer之前对原始文本进行处理,比如增加、删除或替换的字符等。
自带的Character Filters有如下:
html_strip:去除html标签和转换html字体
Mapping:进行字符串替换
Pattern Replace:进行正则匹配替换
如下,指定测试的char_filter为html_strip,分词器为keyword,表示不分词:
1 | POST /_analyze |
服务器返回如下结果:
1 | { |
Tokenizer
将原始文本按照一定的规则切分称为单词。
自带的Tokenizer如下:
standard:按照单词切割
letter:按照非字符切割
whitespace:按照空格切割
UAX URL Eamil 按照standard切割,但不会分割邮箱和url
NGram和Edge NGram:连词分割
path_hierarchy:按照文件路径进行分割
如下,指定测试的Tokenizer为path_hierarchy,对路径/home/heql/elasticsearch-6.5.0进行切分:
1 | POST /_analyze |
服务器返回的结果如下:
1 | { |
Token Filter
是对于Tokenizer输出的单词(term)进行增加、删除、修改等操作。
自带的Token Filter如下:
lowercase:将所有term转化为小写
stop:删除stop word
NGram和Edge NGram:连词分割
Synonym:添加近义词的term
filter可以有多个并按照指定的顺序执行
如下, filter指定使用stop、lowercase、ngram。这里是指定每4位切割一次,min_gram和max_gram分别指定最小和最大的切割位数。
1 | POST /_analyze |
服务器返回的结果如下:
1 | { |
自定义分词的API
自定义分词需要在索引的配置中设定。
如下定义一个my_custom_analyzer分词器,character filter使用html strip、tokenizer使用standard、token filter使用lowarcase和ascii folding:
1 | PUT /test_index |
如下,使用自定义分词器:
1 | POST /test_index/_analyze |
服务器返回的结果如下:
1 | { |
下面character filter使用自定义的mapping:emoticons、 tokenizer使用自定义的punctuation、filter使用自定义的english_stop:
1 | PUT /test_index2 |
如下,使用上面的分词器:
1 | POST /test_index2/_analyze |
服务器返回的结果如下:
1 | { |
分词使用说明
分词一般会在以下的情况下使用:
索引时分词: 创建或更新文档的时候,会对相应的文档进行分词处理。
查询时分词: 查询时,会对查询语句进行分词
明确字段是否需要分词,不需要分词的字段就将type设置为 keyword,可以节省空间和提高写性能。
索引时分词
索引时分词是通过配置Index Mapping中每个字段的analyzer属性实现的,不指定分词时,默认使用standard。
查询时分词
查询时分词的指定方式有如下几种:
查询的时候通过analyzer指定分词器
通过Index Mapping设置search_analyzer实现
一般不需要特别指定查询时分词器,如果不指定,查询时默认使用的是索引时分词器。如果指定的查询时分词器和索引时的分词器不一致,可能出现无法匹配的情况。