在Elasticsearch中,mapping是类似于关系型数据库中的表结构定义。主要作用如下:
定义index下的字段名
定义字段类型,比如数值型、浮点型、布尔型等
定义倒排索引相关的设置,比如是否索引、记录position等
查看mapping
使用如下命令,可以查看test_index的mapping:
GET /test_index/_mapping
服务器返回如下内容,properties表示字段的属性,type表示字段的类型:
1 | { |
自定义mapping
在创建index时,可以设置mapping。mapping中的字段类型一旦设置,禁止直接修改,因为lucene实现的倒排索引生成后不允许修改。应该重新建立新的索引,然后做reindex操作。
dynamic参数
esmapping中的字段类型虽然不可改变,但是可以新增字段,通过dynamic参数来控制字段的新增,这个参数的值如下:
true:默认值,表示允许选自动新增字段
false:不允许自动新增字段,但是文档可以正常写入,但无法对字段进行查询等操作
strict:严格模式,文档不能写入,报错
如下创建一个my_index,包含title、name、age字段:
1 | PUT /my_index |
如下写入一个文档,这里在mapping设置中,”dynamic”: false,表示在写入文档时,如果写入字段不存在也不会报错。desc字段就是不存在的字段:
1 | PUT /my_index/doc/1 |
但无法对desc字段进行查询:
1 | GET /my_index/doc/_search |
服务器返回如下内容:
1 | { |
如果将dynamic设置为strict模式,写入上面mapping中没有定义的desc字段时,写入将会失败:
1 | { |
copy_to参数
是将该字段的值复制到目标字段,实现类似_all的作用。字段不会出现在_source中,只能用来搜索。
如下,创建一个index,将first_name和last_name的内容复制到full_name:
1 | PUT /my_index |
然后创建一个新的文档:
1 | PUT /my_index/doc/1 |
如下,查询full_name字段中包含关键字john smith的文档,必须同时包含两个关键字才返回:
1 | GET /my_index/_search |
服务器返回如下结果:
1 | { |
index参数
index参数作用是控制当前字段是否被索引,默认为true,false表示不记录,即不可被搜索。
当在elasticsearch中存储了一些不想要被检索的字段如身份证、手机等,对于这些字段就可以设置index为false,这样有一定的安全性还可以节省空间。
如下,设置cookie字段的index为false:
1 | PUT /my_index |
创建一个文档:
1 | PUT /my_index/doc/1 |
查询cookie字段时,服务器将会报错:
1 | GET /my_index/_search |
index_options参数
index_options的作用是用于控制倒排索引记录的内容,有如下四种配置:
docs:只记录doc id
freqs:记录doc id 和term frequencies
positions:记录doc id、 term frequencies和term position
offsets:记录doc id、 term frequencies、term position、character offsets
text类型的默认配置为positions,其他类型默认为docs。记录的内容越多,占据的空间越大。
null_value参数
当字段遇到null值的时候的处理策略,默认为null,即空值,此时Elasticsearch会忽略该值。可以通过这个参数设置某个字段的默认值。
如下将cookie的字段默认值设置为NULL:
1 | PUT /my_index |
数据类型
基本数据类型
字符串型:text、keyword(不会分词)
数值型:long、integer、short、byte、double、float、half_float等
日期类型:date
布尔类型:boolean
二进制类型:binary
范围类型:integer_range、float_range、long_range、double_range、date_range
复杂数据类型
数组类型:array
对象类型:object
嵌套类型:nested object
地理位置数据类型:geo_point、geo_shape
专用类型:ip(记录ip地址)、completion(实现自动补全)、token_count(记录分词数)、murmur3(记录字符串hash值)
Dynamic mapping
在写入文档的时候如果index不存在的话elasticsearch会自动创建这个索引, elasticsearch是依靠json文档的字段类型来实现自动识别字段类型的:
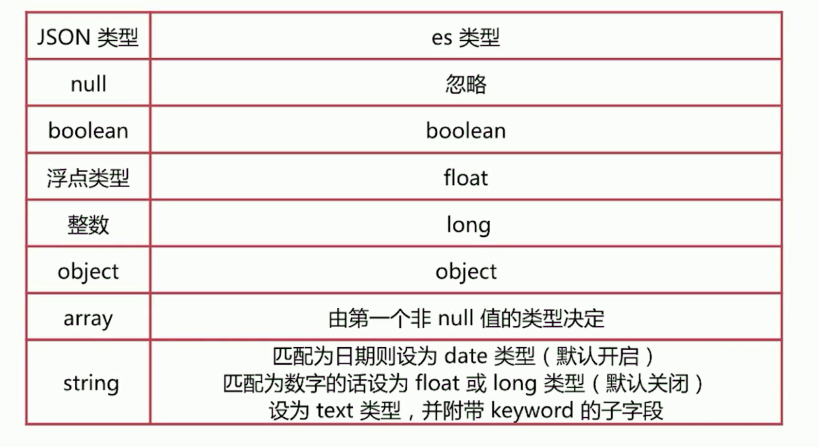
创建如下index的文档:
1 | PUT /test_index/doc/1 |
elasticsearch根据文档创建mapping,对应的mapping如下:
1 | { |
date_detection
通过配置date_detection可以关闭日期自动识别机制(默认开启),dynamic_date_formats可以自定义日期类型 。
日期的自动识别可以自行配置日期的格式,默认情况下是:
["strict_date_opeional_time", "yyyy/MM/dd HH:mm:ss Z||yyyy/MM/dd Z"]
strict_date_opeional_time是ISO 标准的日期格式,完整的格式如下:
YYYY-MM-DDhh:mm:ssTZD (eg:1997-07-16 19:20:30+01:00)
如下定义一个日期的类型为MM/dd/yyyy:
1 | PUT /test_index |
新建文档:
1 | PUT /test_index/doc/1 |
查看mapping,可以看到create_time被识别为date类型:
1 | { |
numeric_detection
字符串为数字的时候,默认不会自动识别为整型,numeric_detection可以开启字符串中数字的自动识别。
如下开启可数字的自动识别:
1 | PUT /test_index |
新建文档:
1 | PUT /test_index/doc/1 |
查看mapping,my_float设置为float、my_integer设置为integer:
1 | { |
Dynamic Templates
Dynamic Templates意为动态模板,它的作用是允许根据elasticsearch自动识别的数据类型、字段名等来动态设定字段类型。
可以实现的效果如下:
所有字符串类型都设置为keyword类型,即默认不分词
所有以message开头的字段都设置为text类型,即分词
所有以long_开头的字段都设置为long类型
所有自动匹配为double类型的都设定为float类型,以节省空间
匹配规则参数:
match_mapping_type:匹配elasticsearch自动识别的字段类型,如boolean、long等
match、unmatch:匹配字段名
path_match、path_unmatch:匹配路径
如下,将以message开头的字段且为string的匹配设置为text类型,其余设置为keyword:
1 | PUT /test_index |
写入文档:
1 | PUT /test_index/doc/1 |
查看mapping,可以看到message被设置为了text类型,name还是keyword:
1 | { |
自定义mapping的建议
自定义mapping 的步骤:
- 写一条文档到elasticsearch的临时索引中,获取es自动生成的mapping
- 修改第一步得到的mapping,自定义相关配置
- 使用第2步的mapping创建所需的索引
假设需要存入如下数据的文档,首先将文档写入临时的index中:
1 | PUT /test_index/doc/1 |
然后查看elasticsearch自动生成的mapping:
GET test_index/_mapping
现在希望将bytes设置为整型,url设置为text类型,其他都使用keyword(将上一步的输出复制过来就好):
1 | PUT /product_index |
然后就可以向实际的索引中写入文档了:
1 | PUT /product_index/doc/1 |
上面的设置方法很直接,但是当字段比较多的时候显得复杂,可以使用动态模板进行匹配,这里使用动态模板匹配所有字符串都设置为keyword类型,需要单独设置类型的在下面另行指出:
1 | PUT /product_index |