search 的运行机制
es在search执行的时候实际分两个阶段,称为Query-then-Fetch:
Query阶段
Fetch阶段
Query阶段
如下图:
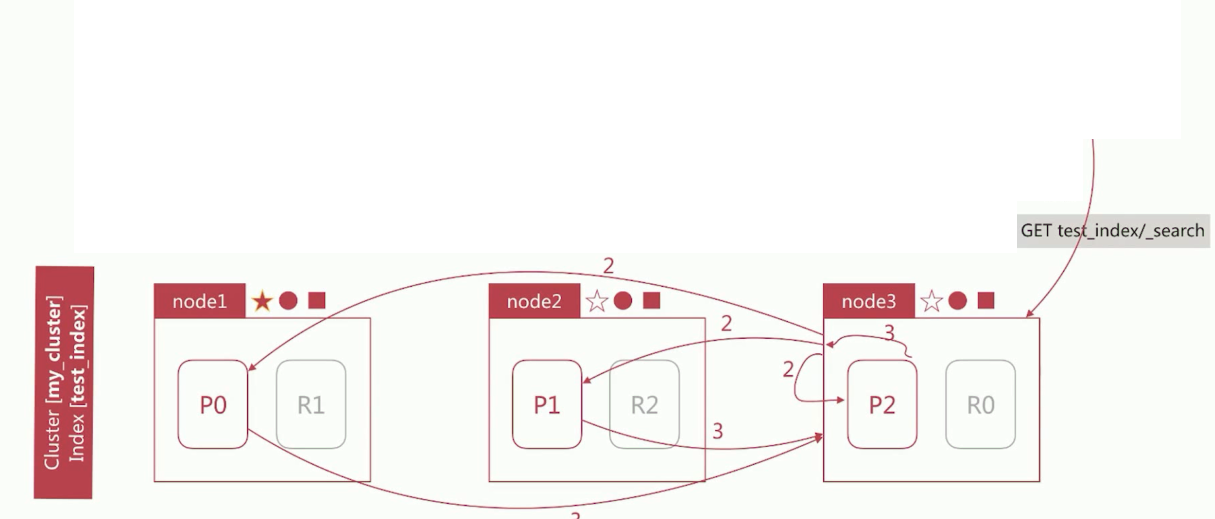
node3(此时是Coordinating Node角色)在接收到用户的search请求后,会先执行Query阶段
node3 在6个主副分片中随机选择3个分片,发送search request
被选中的3个分片会分别执行查询并排序,每个node会返回
from+size个文档id和排序值node3 整合3个分片返回的
from+size个文档id,根据排序后选取from到from+size的文档id
Fetch阶段
如下图:
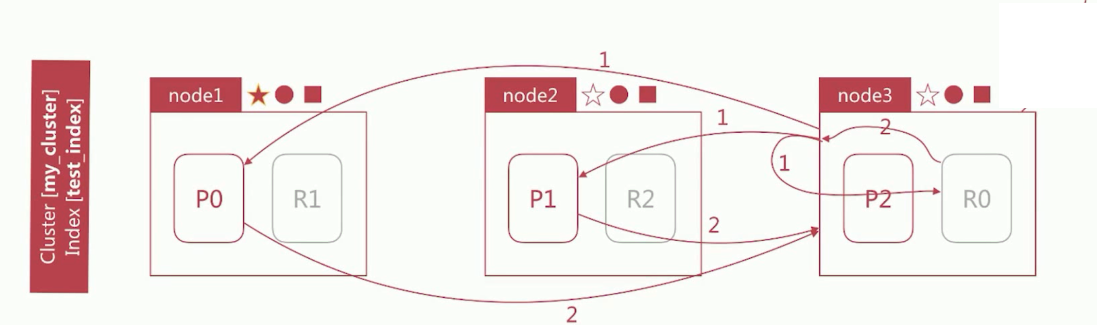
node3 会根据上面Query阶段获取的文档id列表去对应的shard上获取文档详情数据:
node3 向相关的分片发送multi_get请求
3个分片返回文档详细数据
node3 拼接返回的结果并返回给客户
相关性算分问题
相关性算分在shard与shard间是相互独立的,也就意味着同一个term的IDF等值在不同shard上是不同的。文档的相关性算分和它所处的shard相关。
在文档数量不多时,会导致相关性算分严重不准的情况
如下创建3个文档:
1 | POST /test_search_relevance/doc |
在es中如果没有设置shard的大小,默认值为5,执行如下命令可以查看当前shard的大小:"number_of_shards" : "5"
GET /test_search_relevance
如下查询是返回name字段包含hello的文档:
1 | GET /test_search_relevance/_search |
返回的结果如下:
1 | { |
可以看到返回的文档中hello, world! a beautiful world的文档排在最前面,而不是hello的文档。
查看上面查询的相关性算分过程:
1 | GET /test_search_relevance/_search |
从返回的结果可以看到hello, world! a beautiful world在第2个分片上: "_shard" : "[test_search_relevance][2]",文档频率为1: value" : 1.0,。其余的两个文档都在第0个分片上:"_shard" : "[test_search_relevance][0]",文档频率为1: value" : 2.0。因为相关性算分是在不同的shard独立计算的,所以会出现hello, world! a beautiful world文档排在前面。
解决这个问题如下两种:
设置分片数为1,从根本上排除问题,在文档数量不多的时候可以考虑该方案,比如百万到千万级别的文档数量
使用 DFS Query-then-Fetch查询方式
设置分片数为1
如下将number_of_shards设置为1:
1 | DELETE /test_search_relevance |
写入上面的文档后,再执行查询,可以看到查询如下的结果,hello的文档排在最前面:
1 | { |
查看上面查询的相关性算分过程,可以看到3个文档都在同一个分片上,文档频率为1: value" : 3.0。
DFS Query-then-Fetch查询
DFS Query-then-Fetch 是在拿到所有文档后再重新完整的计算一次相关性算分,耗费更多的cpu和内存,执行性能也比较低,一般不建议使用。
如下使用DFS Query-then-Fetch进行查询:
1 | GET /test_search_relevance/_search?search_type=dfs_query_then_fetch |
返回的结果是hello的文档排在最前面。
排序
es默认会采用相关性算分排序,用户可以通过设定sort参数来设定排序规则。
如下是按照birth由大到小进行文档排序:
1 | GET /test_search_index/_search |
服务器将会返回如下内容,可以看到相关性算分_score字段值为null,因为上面的查询是按照birth字段进行排序的,所以相关性算分则无意义:
1 | { |
排序的时候,也可以使用多个字段进行排序,如下按照birth降序排序、如果birth相同,则按照_score排序,如果birth和_score都相同,则按照文档的id排序:
1 | GET /test_search_index/_search |
字符串排序
按照字符串排序比较特殊,因为es有text和keyword两种类型,因为text类型是会分词的,如果直接对text类型进行排序,es将会报错。
如下对text类型的username字段进行排序:
1 | GET /test_search_index/_search |
服务器将会如下出错内容:
reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [username] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead."
如下是使用username中子字段的类型keyword,进行排序,服务器则会返回排序后的结果:
1 | GET /test_search_index/_search |
fielddata
如果要对text类型进行排序,可以开启fielddata,默认是关闭的(可以随时打开或关闭),此时字符串是按照分词后的term排序,但是排序的结果往往很难符合预期,一般是对分词做聚合分析的时候开启。
fielddata只针对text类型,如果用于其他类型将会报错。
如下是开启username中的fielddata:
1 | PUT /test_search_index/_mapping/doc |
此时再对username进行排序:
1 | GET /test_search_index/_search |
返回的结果如下,是按照分词后的结果[way, way, lee, alfred]进行排序的:
1 | { |
分页与遍历
es提供了3种方式来解决分页与遍历的问题:
from/size
scroll
search_after
from/size
from: 指明开始位置、size:指明获取总数
如下是从0开始获取2个文档:
1 | GET test_search_index/_search |
深度分页会存在的问题:如在数据分片存储的情况下如何获取前1000个文档?
当获取从990~1000(from: 990、size: 10)的文档时,会在每个分片上都先获取1000个文档,然后再由Coordinating Node聚合所有分片的结果后再排序选取前1000个文档。
页数越深,处理文档越多,占用内存越多,耗时越长。尽量避免深度分页,es通过index.max.result.window限定最多到10000条数据。
如下指定从10000开始的位置查询2个文档:
1 | GET /test_search_index/_search |
es将会返回如下错误:
"reason": "Result window is too large, from + size must be less than or equal to: [10000] but was [10002]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."
scroll
以快照的方式来避免深度分页的问题:
不能用来做实时搜索,因为数据不是实时的
尽量不要用复杂的sort条件,使用_doc最高效
使用稍微复杂
使用scroll时需要发起1个scroll search,es在收到该请求后会根据查询条件创建文档id合集的快照,返回一个scroll id,然后用户再使用这个scroll id来获取文档集合。
如下是使用scroll查询文档,scroll=5m表示快照的有效时间:
1 | GET /test_search_index/_search?scroll=5m |
es将会返回如下内容:
1 | { |
要获取下一个文档时,需要指定scroll_id为上面es返回的scroll_id:
1 | POST /test_search_index/_search/scroll |
通过这样的迭代,一直遍历到hits为空,即可把所有的文档都遍历完。
因为scroll是以快照生成数据集的,不是实时的,如果在使用scroll遍历文档时,如果有新的文档写入,scroll将不会返回该文档。同理删除文档时,scroll会遍历出过期的文档。
过多的scroll调用会占用大量的内存,可以通过clear删除过多的scroll快照。
如下是删除指定scroll_id:
1 | DELETE /_search/scroll |
如下是删除所有的scroll:
DELETE /_search/scroll/_all
search after
通过唯一排序值定位将每次要处理文档数控制在size内,避免深度分页的性能问题。提供实时的下一页文档获取功能,缺点是不能使用from参数,即不能指定页数,只能下一页、不能上一页。
第一步为正常的搜索,但要指定sort值,并保证值唯一
第二步为使用上一步最后一个文档的sort值进行查询
如下指定sort值为age和_id:
1 | GET /test_search_index/_search |
es返回如下结果:
1 | { |
下次查询时,需要使用上面返回的"sort" : [28,"2"]:
1 | GET /test_search_index/_search |
三种分页使用的场景
| 类型 | 场景 |
|---|---|
| from/size | 需要实时获取顶部的部分文档,且需要自由翻页 |
| scroll | 需要全部文档,如导出所有数据的功能 |
| search_after | 需要全部文档,不需要自由翻页 |