聚合分析,英文为Aggregation,是es除搜索功能外提供的针对es数据做统计分析的功能。
es提供的聚合分析,具备如下特点:
功能丰富,提供bucket、metric、pipeline等多种分析方式,可以满足大部分的分析需求
实时性高,所有的计算结果都是即时返回的,而hadoop等大数据系统一般都是T+1级别的
es将聚合分析主要分为如下4类:
bucket: 分桶类型,类似SQL中的GROUY BY语句
metric: 指标分析类型,如计算最大值、最小值、平均值等
pipeline: 管道分析类型,基于上一级的聚合分析结果进行再分析
matrix: 矩阵分析类型
测试数据
1 | POST /test_search_index/doc/_bulk |
metric
主要分为如下两类:
单值分析,只输出一个分析结果:min、max、avg、sum、cardinality
多值分析,输出多个分析结果:stats、extended stats、percentiles、percentile rank、top hits
近似统计算法
在es的聚合分析中,cardinality和percentile分析使用的是近似统计算法
结果是近似准确的,但不一定精准
可以通过参数的调整使其结果精准,但同时也意味着更多的计算时间和更大的性能消耗
min
返回数值类字段的最小值。
如下是获取所有文档中age的最小值,"size": 0表示不返回文档的内容:
1 | GET /test_search_index/_search |
es将会返回如下的内容:
1 | { |
max
返回数值类字段的最大值。
如下是获取所有文档中age的最大值:
1 | GET /test_search_index/_search |
avg
返回数值类字段的平均值。
如下是获取所有文档中age的平均值:
1 | GET /test_search_index/_search |
sum
返回数值类字段的总和。
如下是获取所有文档中age的总和:
1 | GET /test_search_index/_search |
多个聚合分析
在一次的请求中可以指定多个聚合分析。
如下是获取所有文档中age的最小值、最大值、平均值、总和:
1 | GET /test_search_index/_search |
es将会返回每个聚合分析的结果:
1 | { |
cardinality
意为基数,是指不同数值的个数,类似于SQL中的distinct count(去重之后的个数)概念。
如下是获取所有文档中job的个数:
1 | GET /test_search_index/_search |
stats
返回一系列数值类型的统计值,包含min、max、avg、sum和count。
如下是获取所有文档中age的stats:
1 | GET /test_search_index/_search |
es返回如下结果:
1 | { |
extended stats
对stats的扩展,包含了更多的统计数据,如方差、标准差等。
如下是获取所有文档中salary的extended stats:
1 | GET /test_search_index/_search |
es返回如下结果:
1 | { |
percentiles
百分位数统计。
如下是获取所有文档中salary的percentiles:
1 | GET /test_search_index/_search |
es返回如下结果:1%的salary为5000.0, 5%的salary为5000.0, 25%的salary为8000.0等,返回的百分比可能有所差异,因为这跟es的概率统计算法有关。
1 | { |
也指定返回指定百分比的数据,如下是指定返回百分之95、99、99.9的数据:
1 | GET /test_search_index/_search |
percentile rank
相应数值的百分比。
如下是获取所有文档中salary为11000、30000的占比:
1 | GET /test_search_index/_search |
top hits
一般用于分桶后获取该桶内最匹配的顶部文档列表,即详情数据:
如下是获取按job分桶后、按age降序排列后的前10个文档:
1 | GET /test_search_index/_search |
bucket
bucket意为桶,即按照一定的规则将文档分配到不同的桶中,达到分类分析的目的。
按照bucket的分桶策略,常见的bucket聚合分析如下:
terms
range
date range
histogram
date histogram
terms
直接按照term来分桶,如果是text类型,则按照分词后的结果分桶。
如下是对job.keyword进行分桶:
1 | GET /test_search_index/_search |
es返回的结果如下:
1 | { |
range
通过指定数值的范围来设定分桶规则。
如下是对salary小于10000、10000-20000、大于20000进行分桶,key表示自定义es返回的key:
1 | GET /test_search_index/_search |
es返回如下结果:
1 | { |
date range
通过指定日期的范围来设定分桶规则
如下对birth的按日期范围进行分桶:
1 | GET /test_search_index/_search |
histogram
直方图,以固定间隔的来分隔数据
如下是salary按5000的间隔来分隔数据,最小的值为0,最大的值为40000:
1 | GET /test_search_index/_search |
date histogram
针对日期的直方图或者柱状图,是时序数据分析中常用的聚合分析类型:
1 | GET /test_search_index/_search |
bucket的子分析
bucket聚合分析允许通过添加子分析来进一步分析,该子分析可以是bucket也可以是metric。这也使得es的聚合分析能力变得异常强大。
分桶后再分桶
如下是对job先进行分桶,然后再针对job分桶后的结果按age再进行分桶:
1 | GET /test_search_index/_search |
分桶后进行数据分析
如下是对job先进行分桶,然后再针对job分桶后的结果进行salary的stats分析:
1 | GET /test_search_index/_search |
pipeline
针对聚合分析的结果再次进行聚合分析,而且支持链式调用。
pipeline的分析结果会输出到原结果中,根据输出位置的不同,分为以下两类:
Parent: 结果内嵌到现有的聚合分析结果中
derivative(求导)
moving average(移动平均)
cumulative sum(累加求和)
sibling: 结果与现有聚合分析结果同级:
max/min/avg/sum/bucket
stats/extended stats bucket
percentiles bucket
sibling
min_bucket
如下是找出按照job的分桶后计算的平均的salary(min_salary_by_job是对job集合分析后的结果再次做集合分析):
1 | GET /test_search_index/_search |
es返回如下结果:
1 | { |
其他
其余的max_bucket、avg_bucket、sum_bucket、stats_bucket使用的语法是类似的。
parent
derivative
计算bucket值的导数:
1 | GET /test_search_index/_search |
其他
moving_age、cumulative_sum的语法与derivative是类似的。
作用范围
es 聚合分析默认作用范围是query的结果集,可以通过如下方式改变其作用范围:
filter
post-filter
global
如下aggs作用于query的结果集:
1 | GET /test_search_index/_search |
filter
为某个聚合分析设定过滤条件,从而在不更改整体query语句的情况下修改了作用范围。
如下jobs_salary_small是设置filter的聚合分析,jobs是没有设置filter的聚合分析,可以从返回的结果可以看出两个区别jobs_salary_small将会过滤掉salary小于10000的结果:
1 | GET /test_search_index/_search |
post filter
作用于文档过滤,但在聚合分析后生效。
如下是对job分桶后的结果进行过滤:
1 | GET /test_search_index/_search |
global
无视query过滤条件,基于全部文档进行分析:
如下java_avg_salary返回的是java engineer的平均salary,all返回的所有人的平均salary:
1 | GET /test_search_index/_search |
排序
可以使用对聚合分析的结果进行排序。
如下是对job进行分桶后,按照文档的数据进行升序排序,如果文档的数量相同,在按照key进行降序排序:
1 | GET /test_search_index/_search |
如下是对job进行分桶,再按照平均salary进行降序排序:
1 | GET /test_search_index/_search |
如下是对job进行分桶,再按照stats分析后的stats_salary的总和进行降序排序:
1 | GET /test_search_index/_search |
如下是对salary进行分桶,过滤掉age小于10的文档,再求平均的age,最后按平均age进行排序:
1 | GET /test_search_index/_search |
计算精准度问题
min聚合分析的执行流程
如下是min聚合分析的执行的流程图:
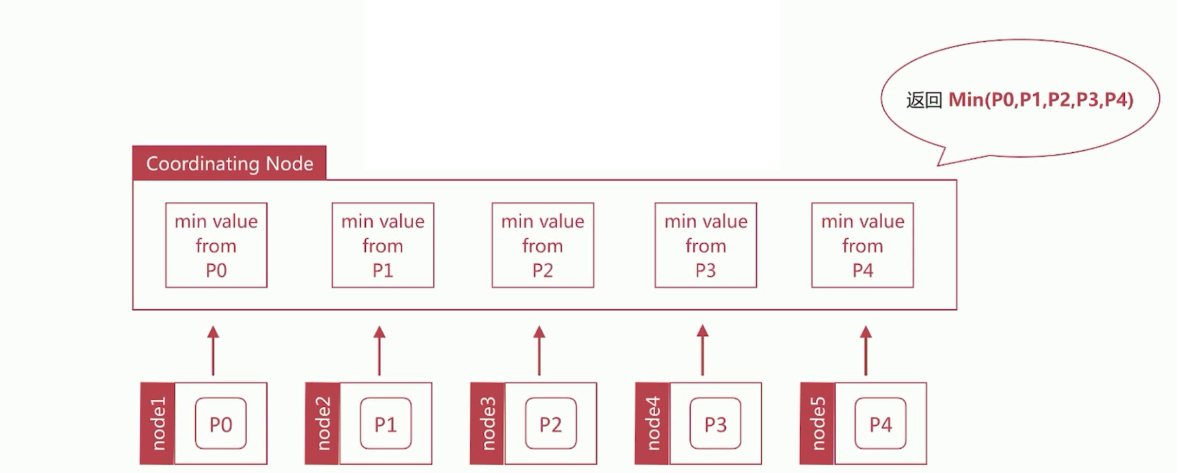
假设es存在有5个分片,在执行min聚合分析时,es首先会获取每个分片上的最小值,然后再对每个分片合并后的结果,取出最小的值返回给用户。
terms聚合分析的执行流程
如下图:
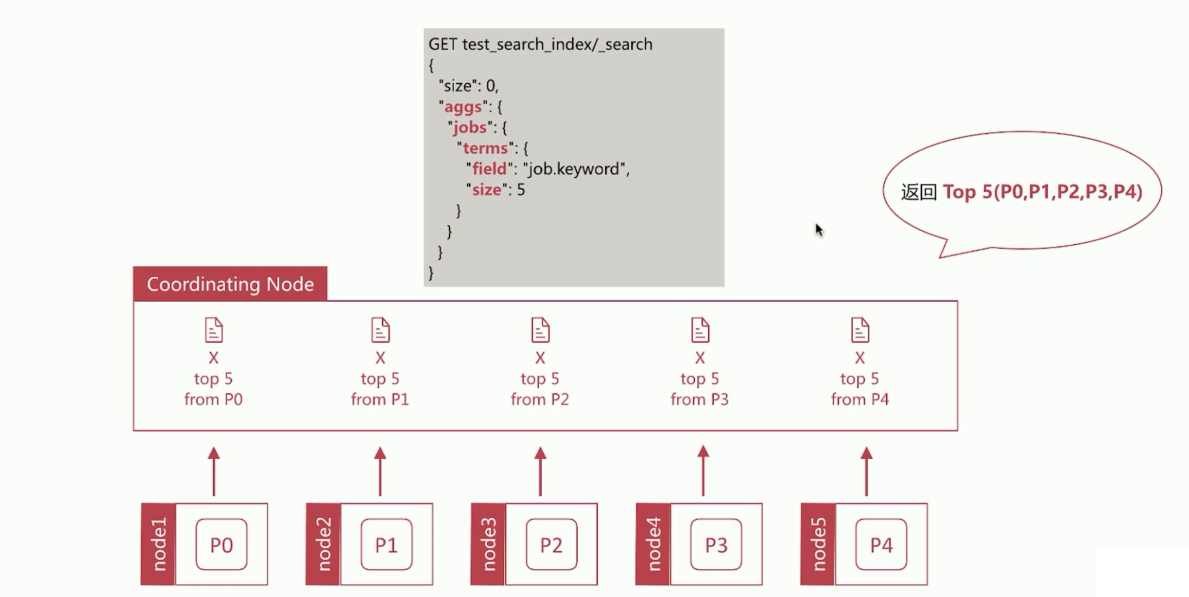
与min的执行流程类型,但是terms返回的结果并不永远正确。
如下图,在2个分片上执行terms的聚合分析,要求返回top3的数据,在P0分片上返回的是[a, b, d]、在P1分片上返回的是[a, b, c],最终返回的结果是[a, b, d],但是c文档的数据分布在2个分片上,总数为6,要比d文档总数4多,所以真正的结果是[a, b, c]:
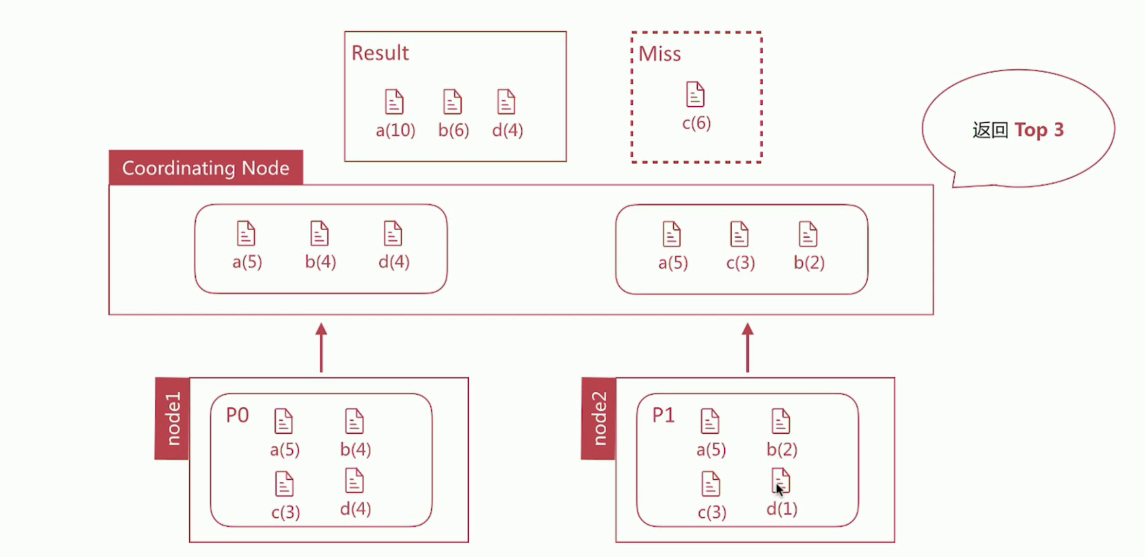
因为数据分散在多个分片上,Coordinating Node无法得悉数据的全貌,所以terms返回的结果并不永远正确。
解决办法
设置分片数为1,消除数据分散的问题,但无法承载大数据量
合理设置shard_size大小,即每次从shard上额外多获取数据,以提升正确度
如下是要求es返回top5的数据,但是在每个分片上获取的数据是10个:
1 | GET /test_search_index/_search |
shard_size大小的设定方法
terms聚合返回结果中有如下两个统计值,可以根据这两个统计值来合理的调整shard_size的大小:
doc_count_error_upper_bound: 被遗漏的term可能的最大值
sum_other_doc_count: 返回结果bucket的tem外其他term的文档总数
通过设定show_term_doc_count_error可以查看每个bucket误算的最大值
1 | GET /test_search_index/_search |
es会用doc_count_error_upper_bound字段来标识每个bucket的误算值:
1 | { |
shard_size默认大小为: shard_size = (size * 1.5) + 10
通过调整shard_size的大小降低doc_count_error_upper_bound来提升准确度,会增大整体的计算量,从而降低响应时间