Logstash是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到Elasticsearch等存储库。
架构
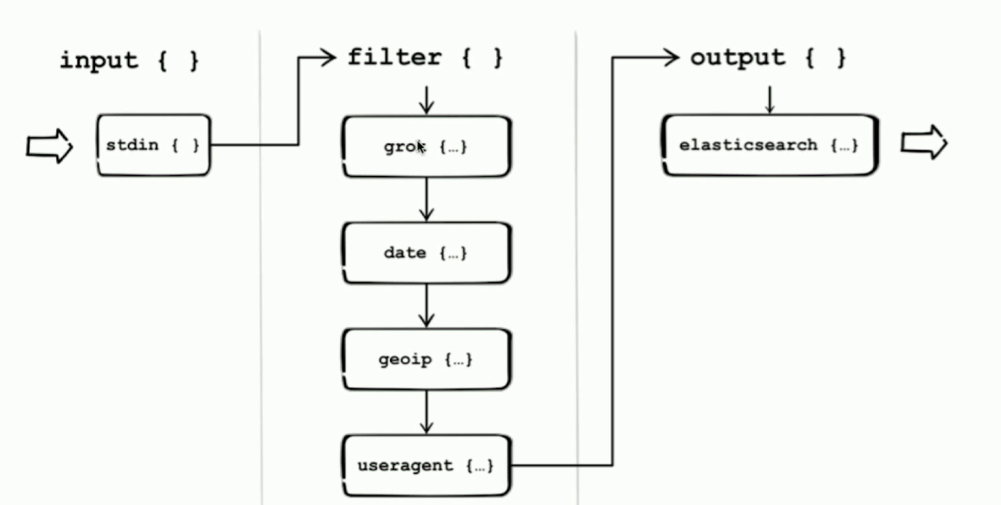
Logstash由如下3部分组成:
input: 用于数据采集
filter: 数据解析/转换
output: 数据输出
相关名词
pipeline: 一条数据处理流程的逻辑抽象(input->filter->output的3阶段处理流程)。
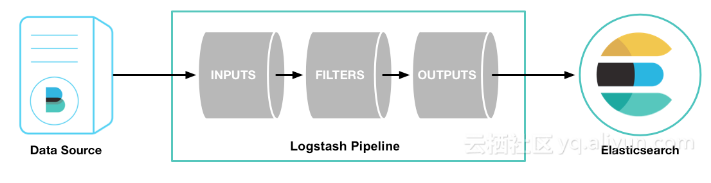
event: 原始数据在input被转换为event,在output event被转换为目标格式数据。

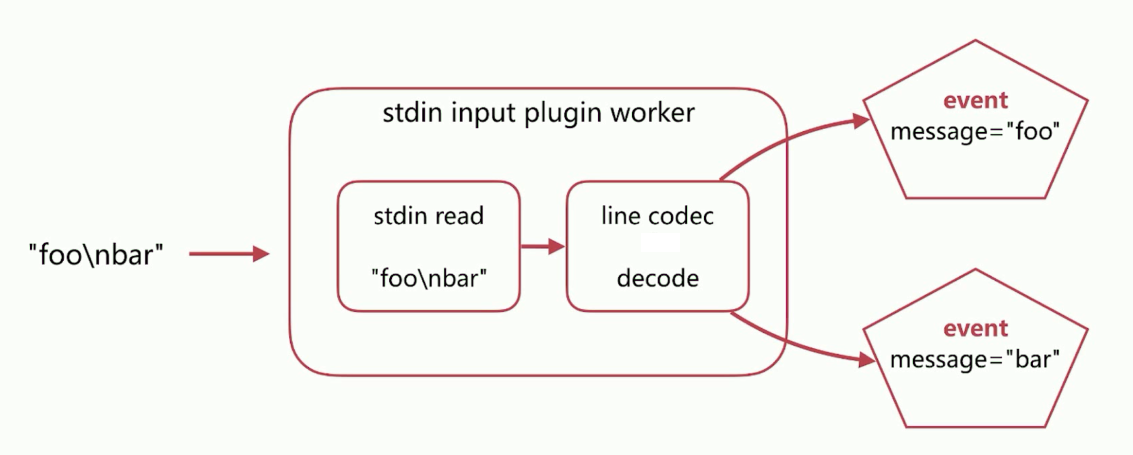
如下的codec.conf配置:
input {
stdin {
codec => line
}
}
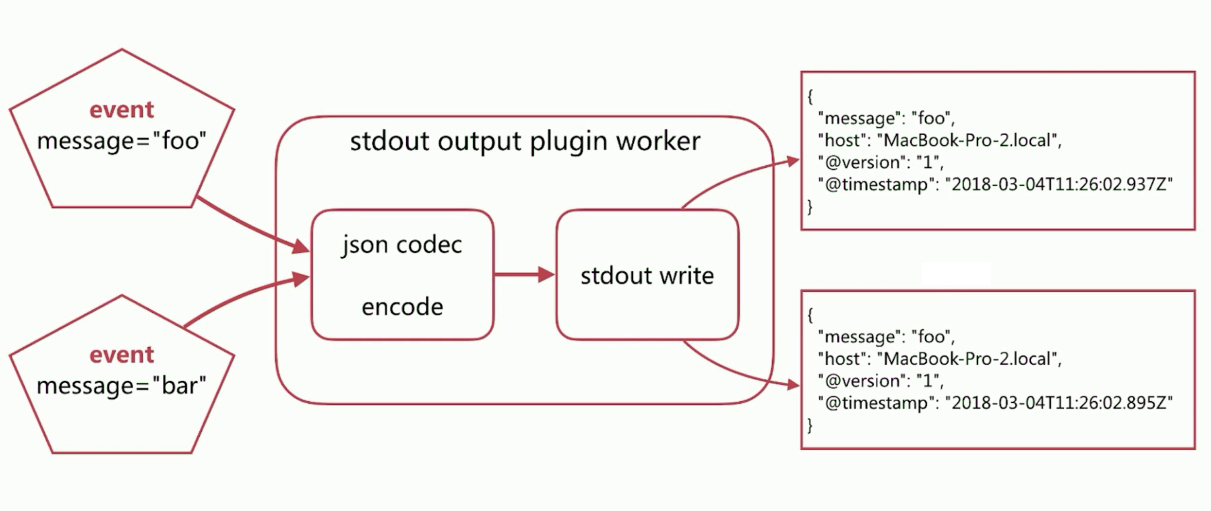
output {
stdout {
codec =>json
}
}
当在标注输入foo\nbar后,input插件将会读取数据,然后通过line codec decode(按行分隔)将分为foo和bar两个event:
当foo和bar两个event,经过json codec encode后最终会输出如下的json内容:
queue
如下图,logstash从input中读取通过codec解析成event后,会将解析后的event放入到Queue中,Batcher负责批量的从queue中取数据,当Batcher中数据到达一定量或一定时间后,将会发送给filter,filter最终发送给output。
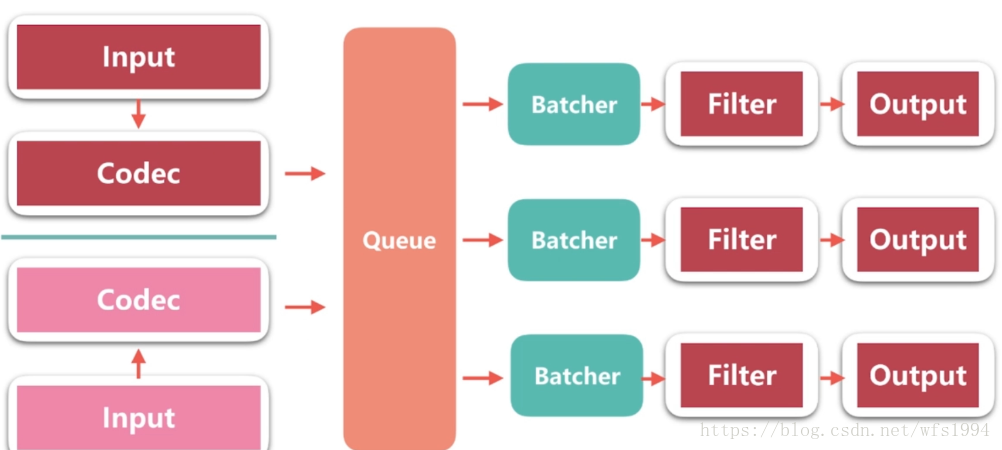
Queue可以分为以下两种:
In Memory: 所有的数据都存储在内存中,如果出现进程Crash或者机器宕机,会导致数据丢失
Persist Queue In Disk: 在数据存储在内存中,会备份一份数据在磁盘中,当数据在output处理完后,output会通知queue删除磁盘中的数据。这样就可处理进程Crash等情况,保证数据不丢失,保证数据至少消费一次。
持久队列的相关配置:
queue.type:persisted #默认是memory
queue.max_bytes:4gb #队列存储最大数据量
thread
logstash的线程可以分为两种:
input thread
pipeline thread
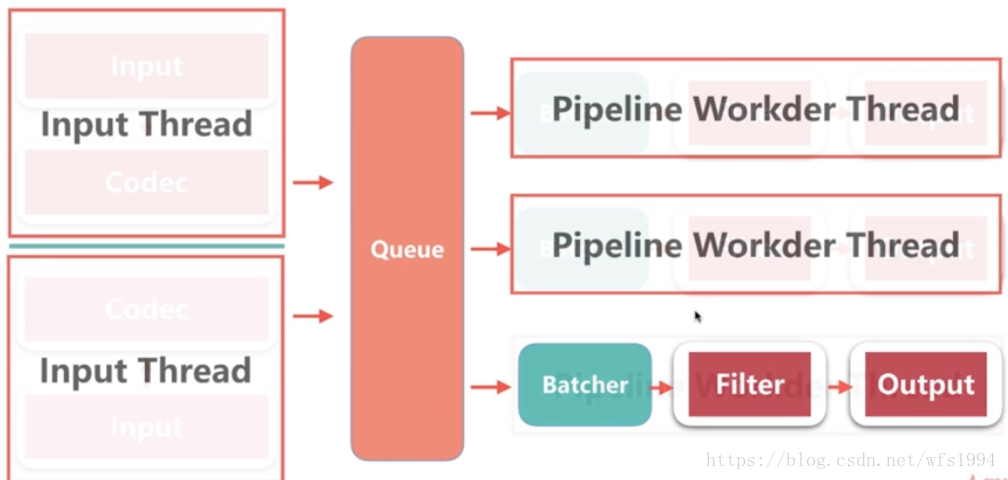
相关配置:
pipeline线程数,即filter_output的处理线程数,默认是cpu核数:
pipeline.worksers (配置文件)| -w (命令行参数)
Batcher一次批量获取的待处理文档数,默认是125,可以根据输出进行调整,越大会占用越多的heap空间,可以通过jvm.options调整:
pipeline.batch.size (配置文件) | -b (命令行参数)
Batcher等待的时长,单位为ms:
pipeline.batch.delay (配置文件) | -u (命令行参数)
配置文件
logstash设置相关的配置文件(在config目录下):
logstash.yml:logstash相关配置,比如
node.name、path.data、pipeline.workers、queue.type等,这其中的配置可以被命令行参数中的相关参数覆盖jvm.options:修改jvm的相关参数,比如修改heap size等
pipeline配置文件:定义数据处理流程的文件,以.conf结尾
logstash.yml常用配置项
| 配置项 | 含义 |
|---|---|
| node.name | 节点名称,便于识别 |
| path.data | 持久化存储数据的文件夹,默认是logstash home目录下的data |
| path.config | 设定pipeline配置文件的目录(如果指定文件夹,会默认把文件夹下的所有.conf文件按照字母顺序拼接为一个文件) |
| path.log | 设定pipeline日志文件的目录 |
| pipeline.workers | 设定pipeline的线程数(filter+output),优化的常用项 |
| pipeline.batch.size/delay | 设定批量处理数据的数据和延迟 |
| queue.type | 设定队列类型,默认是memory |
| queue.max_bytes | 队列总容量,默认是1g |
pipeline配置
用于配置input、filter和output插件,框架如下所示:
input {}
filter {}
output {}
配置语法
数据类型
主要有如下的数据类型:
布尔类型:
isFailed => true
数值类型:
port => 33
字符串类型:
name => "Hello world"
数组:
users => [{id => 1, name => "bob"}, {id => 2, name => "jane"}]
path => ["/var/log/messages", "/var/lg/*.log"]
哈希类型:
match => {
"field1" => "value1",
"field1" => "value2"
}
注释:
# this is comment
引用logstash event属性
在配置中可以引用logstash event的属性(字段),主要有如下两种方式:
直接引用字段值:使用
[]即可,嵌套字段写多层[]:if [request] = ~"index" {} if [ua][os] = ~"windows" {}在字符串中以sprintf方式引用,使用%{}来实现:
req => "request is %{request}" ua => "ua is %{[ua][os]}"
条件判断
支持条件判断语法,从而扩展了配置的多样性,主要格式如下:
if EXPRESSION {
...
} else if EXPRESSION {
...
} else {
...
}
表达式
表达式主要包含如下的操作符:
比较: ==、!=、<、> 、<=、>=
正则是否匹配: =~、!~
包含(字符串或者数组): in、not in
布尔操作符: and、or、nand、xor、!
分组操作符: ()
if [action] == "login" {} if [loglevel] == "ERROR" and [deployment] == "production" {} if [foo] in [foobar] {} if [foo] in "foo" {} if "hello" in [greeting] {} if [foo] in ["hello", "world", "foo"] {} if !("foo" in ["hello", "world"]) {} if "failure" not in [tags] {}